At loopbio we maintain some linux packages for use with the conda package manager. These can
replace the original packages present in the community-driven conda-forge channel, while retaining
full compatibility with the rest of the packages in the conda-forge stack. They include some
useful modifications that make them more suited to us, but that we find difficult to submit
"upstream" for inclusion in the respective official packages.
Why might our packages be useful to you?
The default OpenCV packages provided in conda are GPL due to their dependence
on the conda provided FFMPEG which is build as GPL.
If you are using these packages in your code, then your code is GPL
(upon distribution, by the safest interpretation of the license).
If you want to be sure that your code is GPL free, then use our matching LGPL-ffmpeg and OpenCV
packages.
You wish you control the number of threads OpenCV uses (via FFMPEG) for video decoding.
At the time of writing this note, we are actively maintaining three packages:
ffmpeg: provides a LGPL alternative to avoid "viral" licenses in your codebase if
you depend on ffmpeg but do not need H.264 encoding.
opencv: works against any of our ffmpeg variants (giving more licensing freedom)
and also using turbo for jpeg (de)compression, it also adds a few other goodies like replacing openmp
with TBB as the threading managing solution or including a patch to enable controlling
multi-threading when using opencv as a video decoding frontend to ffmpeg.
We have written a getting started with Conda guide here. If you
are already familiar with conda then replacing your conda-forge packages with ours is a breeze.
Using your command line:
# Before getting our conda packages, get a conda-forge based environment.
# For example, use conda-forge by default for all your environments.
conda config --add channels conda-forge
# install and pin ffmpeg GPL (including libx264)...
conda install 'loopbio::ffmpeg=*=*gpl*'# ...or install and pin ffmpeg LGPL (without libx264)
conda install 'loopbio::ffmpeg=*=*lgpl*'# install and pin libjpeg-turbo
# note, this is not needed for opencv to use libjpeg-turbo
conda install 'loopbio::libjpeg-turbo=1.5.90=noclob_prefixed_gcc48_*'# install and pin opencv
conda install 'loopbio::opencv=3.4.3=*h6df427c*'
If you use these packages and find any problem, please let us know using each package issue tracker.
Example: controlling ffmpeg number of threads when used through OpenCV VideoCapture
We have added an environment variable OPENCV_FFMPEG_THREAD_COUNT that controls
ffmpeg's thread_count, and a capture read-only property cv2.CAP_PROP_THREAD_COUNT
that can be queried to get the number of threads used by a VideoCapture object.
The reason why an environment variable is needed and the property is read only is
that the number of threads is a property that needs to be set early in ffmpeg's
lifecycle and should not really be modified once the video reader is open. Note that
threading support actually depends on the codec used to encode the video (some codecs might,
for example, ignore setting thread_count). At the moment we do not support changing
the threading strategy type (usually one of slice or frame).
The following are a few functions that help controlling the number of threads used by ffmpeg
when decoding a video via opencv VideoCapture objects.
"""OpenCV utils."""importcontextlibimportosimportcv2importlogging_log=logging.getLogger(__package__)@contextlib.contextmanagerdefcv2_num_threads(num_threads):"""Context manager to temporarily change the number of threads used by opencv."""old_num_threads=cv2.getNumThreads()cv2.setNumThreads(num_threads)yieldcv2.setNumThreads(old_num_threads)# A string to request not to change the current value of an envvarUSE_CURRENT_VALUE=object()@contextlib.contextmanagerdefenvvar(name,value=USE_CURRENT_VALUE):""" Context manager to temporarily change the value of an environment variable for the current process. Remember that some envvars only affects the process on startup (e.g. LD_LIBRARY_PATH). Parameters ---------- name : string The name of the environment value to modify. value : None, `cv2utils.USE_CURRENT_VALUE` or object; default "USE_CURRENT_VALUE" If `cv2utils.USE_CURRENT_VALUE`, the environment variable value is not modified whatsoever. If None, the environment variable value is temporarily removed, if it exists. Else, str(value) will be temporarily set as the value for the environment variable Examples -------- When a variable is not already set... >>> name = 'AN_ENVIRONMENT_VARIABLE' >>> with envvar(name, None): ... print(os.environ.get(name)) None >>> with envvar(name, USE_CURRENT_VALUE): ... print(os.environ.get(name)) None >>> with envvar(name, 42): ... print(os.environ.get(name)) 42 >>> print(os.environ.get(name)) None When a variable is already set... >>> os.environ[name] = 'a_default_value' >>> with envvar(name, USE_CURRENT_VALUE): ... print(os.environ.get(name)) a_default_value >>> with envvar(name, None): ... print(os.environ.get(name)) None >>> print(os.environ.get(name)) a_default_value >>> with envvar(name, 42): ... print(os.environ.get(name)) 42 >>> print(os.environ.get(name)) a_default_value """ifvalueisUSE_CURRENT_VALUE:yieldelifnamenotinos.environ:ifvalueisnotNone:os.environ[name]=str(value)yielddelos.environ[name]else:yieldelse:old_value=os.environ[name]ifvalueisnotNone:os.environ[name]=str(value)else:delos.environ[name]yieldos.environ[name]=old_valuedefffmpeg_thread_count(thread_count=USE_CURRENT_VALUE):""" Context manager to temporarily change the number of threads requested by cv2.VideoCapture. This works manipulating global state, so this function is not thread safe. Take care if you instantiate capture objects with different thread_count concurrently. The actual behavior depends on the codec. Some codecs will honor thread_count, while others will not. You can always call `video_capture_thread_count(cap)` to check whether the concrete codec used does one thing or the other. Note that as of 2018/03, we only support changing the number of threads for decoding (i.e. VideoCapture, but not VideoWriter). Parameters ---------- thread_count : int or None or `cv2utils.USE_CURRENT_VALUE`, default USE * if None, then no change on the default behavior of opencv will happen on opencv 3.4.1 and linux, this means "the number of logical cores as reported by "sysconf(SC_NPROCESSORS_ONLN)" - which is a pretty aggresive setting in terms of resource consumption, specially in multiprocess applications, and might even be problematic if running with capped resources, like in a cgroups/container, under tasksel or numactl. * if an integer, set capture decoders to the specifiednumber of threads usually 0 means "auto", that is, let ffmpeg decide * if `cv2utils.USE_CURRENT_VALUE`, the current value of the environment variable OPENCV_FFMPEG_THREAD_COUNT is used (if undefined, then the default value given by opencv is used) """returnenvvar(name='OPENCV_FFMPEG_THREAD_COUNT',value=thread_count)defcv2_supports_thread_count():"""Returns True iff opencv has been built with support to expose ffmpeg thread_count."""returnhasattr(cv2,'CAP_PROP_THREAD_COUNT')defvideo_capture_thread_count(cap):""" Returns the number of threads used by a VideoCapture as reported by opencv. Returns None if the opencv build does not support this feature. """try:# noinspection PyUnresolvedReferencesreturncap.get(cv2.CAP_PROP_THREAD_COUNT)exceptAttributeError:returnNonedefopen_video_capture(path,num_threads=USE_CURRENT_VALUE,fail_if_unsupported_num_threads=False,backend=cv2.CAP_FFMPEG):""" Returns a VideoCapture object for the specified path. Parameters ---------- path : string The path to a video source (file or device) num_threads : None, int or `cv2utils.USE_CURRENT_VALUE`, default None The number of threads used for decoding. If None, opencv defaults is used (number of logical cores in the system). If an int, the number of threads to use. Usually 0 means "auto", 1 "single-threaded" (but it might depend on the codec). fail_if_unsupported_num_threads : bool, default False If False, an warning is cast if num_threads is not None and setting the number of threads is unsupported either by opencv or the used codec. If True, a ValueError is raised in any of these two cases. backend : cv2 backend or None, default cv2.CAP_FFMPEG If provided, it will be used as preferred backend for opencv VidecCapture """ifnum_threadsisnotNoneandnotcv2_supports_thread_count():message=('OpenCV does not support setting the number of threads to %r; ''use loopbio build'%num_threads)iffail_if_unsupported_num_threads:raiseValueError(message)else:_log.warn(message)withffmpeg_thread_count(num_threads):ifbackendisnotNone:cap=cv2.VideoCapture(path,backend)else:cap=cv2.VideoCapture(path)ifcapisNoneornotcap.isOpened():raiseIOError("OpenCV unable to open %s"%path)ifnum_threadsisUSE_CURRENT_VALUE:try:num_threads=float(os.environ['OPENCV_FFMPEG_THREAD_COUNT'])except(KeyError,TypeError):num_threads=Noneifnum_threadsisnotNoneandnum_threads!=video_capture_thread_count(cap):message='OpenCV num_threads for decoder setting to %r ignored for %s'%(num_threads,path)iffail_if_unsupported_num_threads:raiseValueError(message)else:_log.warn(message)returncap
If you get these functions, you can open and read capture like this:
1
2
3
4
# Do whatever you needifnotcap.isOpened():raiseException('Something is wrong and the capture is not open')retval,image=cap.read()
Here at loopbio gmbh we use and recommend the Python
programming language. For image processing our primary choice is Python + OpenCV.
Customers often approach us and ask what stack we use and how we set up our
environments. The short answer is: we use conda and
have our own packages for OpenCV and FFmpeg.
In the following post, we will bravely explain how easy it is to set up a
Conda environment for image processing using miniconda
and our packages for OpenCV and a matched FFmpeg version on Linux (Ubuntu).
If you are not familiar with the concept of Conda: Conda is a package manager and
widely used in science, data analysis and machine learning, additionally, it is
fairly easy and convenient to use.
If you are more interested in why we are using OpenCV, FFmpeg and Conda and
what performance benefits you can expect from our packages please check out
our other posts.
In your Terminal window, run: bash Miniconda3-latest-Linux-x86_64.sh
Follow the prompts on the installer screens.
If you are unsure about any setting, accept the defaults. You can change them later.
To make the changes take effect, close and then re-open your Terminal window.
Test your installation (a list of pacakages should be printed). conda list
# Before getting our conda packages, get a conda-forge based environment.# For example, use conda-forge by default for all your environments.
conda config --add channels conda-forge
# Create a new conda environment
conda create -n loopbio
# Source that environmentsource activate loopbio
# install FFmpeg# install and pin ffmpeg GPL (including libx264)...
conda install 'loopbio::ffmpeg=*=gpl*'# ...or install and pin ffmpeg LGPL (without libx264)
conda install 'loopbio::ffmpeg=*=lgpl*'# install and pin opencv
conda install 'loopbio::opencv=3.4.1'
Reading a video file
# Make sure that the loopbio environment is activatedsource activate loopbio
# Start Python
python
In the previous installment of our series on Video I/O we threatened thorough
benchmarks of video codecs. This series of blog posts is about ways to minimize delays
in bringing video frames both to the browser and to video analysis programs, including
training deep learning models from video data. In that post we showed plots like this one:
We used and will keep using what we called "exploded jpeg" as a baseline when talking about
video compression, as encoding images as jpeg is, by far, the most commonly way to transport image
data around in deep learning workloads. Because encoding and, more specially, decoding
are important core operations for us in loopy, and also because we want to give ourselves
a hard time trying to beat baselines, we strive to use the best possible software
for encoding and decoding jpeg data.
So what is the fastest way to read and write jpeg images these days? And how
can we get to use it in the most effective way? In this post we demonstrate
that using libjpeg-turbo is the way to go, presenting the first independent benchmark
(to our knowledge) of the newest jpeg turbo version and touching on a few related issues,
from python bindings to libjpeg-turbo to accelerated python and libjpeg-turbo conda packages.
So let's get started, shall we.
The Contenders
We are going to look across four dimensions here: libjpeg vs libjpeg-turbo,
current stable version of libjpeg-turbo (1.5.3) vs the upcoming version (2.0),
using libjpeg-turbo with different python wrappers, and using libjpeg-turbo
with different parameters controlling the tradeoff between decoding speed
and accuracy. On each round there will be a winner that gets to compete
in the next one.
There is one main open source library used for jpeg encoding: libjpeg. And there is one
main alternative to libjpeg for performance critical applications: libjpeg-turbo. Turbo
is a fork of libjpeg where a lot of amazing optimization work has been done to accelerate
it. Turbo works for many different computer architectures, and used to be a "drop-in"
replacement for libjpeg. This stopped being true when libjpeg decided to adopt some non-standard
techniques - perhaps hoping for them to become one day part of the jpeg standard.
Turbo decided not to follow that path. In principle this means that there might be some
non-standard jpeg images that turbo won't be able to decode[1]_.
However, given the prevalence of turbo in mainstream software (for example, it is used in
web browsers like firefox and chrome, and is a first class citizen in most linux
distributions), it is unlikely these incompatibilities will be seen in the wild.
Having decided that libjpeg-turbo is to be used, we turn our attention to the python
wrapper used on top of it. Our codebase has a strong pythonic aroma and therefore
we are most interested on reading and writing jpegs from python code. Therefore we are using libjpeg,
which is a C library, wrapped in python. We look here at two main wrappers: opencv, which we use as the
go-to library for reading images, and a simple ctypes wrapper (modified from
pyturbojpeg).
The simple ctypes wrapper exposes more libjpeg specific functionality from the wrapped C library
such as faster but less accurate decoding modes. Usually these modes are deactivated by default,
since they result in "less pleasant" images (for humans) in some circumstances. However
certain algorithms might not notice these differences - for example tensorflow activates some
of them by default under the (likely unchecked) premise that it won't matter for model performance.
The Benchmark
To measure how fast different versions of the libjpeg library can compress and
decompres, we have used 23 different images from a public image compression benchmark dataset,
some of our clients videos and even pictures of ourselves. We used these images at three different sizes,
corresponding (without modifying the aspect ratio) to 480x270 (small), 960x540 (medium)
and 1920x1080 (large) resolutions. We always used YUV420 as encoded color space and BGR
as pixel format.
The following are three images from our benchmark dataset, at "medium" size, as originally
presented to the codecs and after compression + decompression (with jpeg encoding quality set at 95
and using the fastest and less precise libjpeg-turbo decoding settings). Can you tell which one
is the original and which one is the round-tripped version? (note, we have shuffled these a bit
to make the challenge more interesting).
All data in this post is summarized results across all images, but it is important to note that
when dealing with compression, results might vary substantially depending on the kind of images
to be stored. In specific cases, such as when all images are similar, which might happen
when storing video data as jpegs, it might be useful to select encoding/decoding
parameters taylored to the data.
For each image and codec configuration we measured multiple times the round-trip
encoding-decoding speed with randomized measurement order. We have checked that
each roundtrip provides acceptable quality results using perceptual image comparison
between the original image and the roundtripped one.
We have timed speed when using libjpeg and libjpeg turbo via python wrappers and subsequently
the measurements always include some python specific costs - such as the time taken to allocate
memory to hold the results. It is expected some speedups can be achieved by optimizing these
wrappers memory usage strategies. We only measure speeds for image data already in RAM and that
is expected to be "cache-warm", so these microbenchmarks represent a somehow idealized
situation and should better be complemented with I/O and proper workload context.
All measurements were made on a single core of an otherwise idle machine,
sporting an intel i7-6850K and fairly slow RAM.
The Results
Encoding Speed
The following table shows average space savings for the benchmarked encode qualities.
These are identical for all the libjpeg variants used and are compared against the space
taken by the uncompressed image.
Encode Quality
Average Space Savings
80
94.1 ± 2.8
95
87.2 ± 5.4
99
77.6 ± 8.4
Before showing our results summary, let us enumerate again the contenders:
turbo_stable: ctypes wrapper over libjpeg-turbo stable (1.5.3)
turbo_beta: ctypes wrapper over libjpeg-turbo 2.0 beta1 (1.5.90)
turbo_beta_fast_dct: like turbo_beta, activating "fast DCT" decoding for all passes
turbo_beta_fast_upsample: like turbo_beta, activating "fast upsampling" decoding
turbo_beta_fast_fast: like turbo_beta, activating both "fast DCT" and "fast upsampling"
The following plot shows how encoding speed varies across different compression qualities
(you can show and hide contenders by clicking in the legend). We can see how
libjpeg-turbo is a clear winner. opencv_without_turbo is doing the same job
as its turbo counterpart opencv_with_turbo, just between 3 and 7 times slower. There
is a second relatively large gap between using opencv or using directly turbo
via ctypes, indicating that for high performance applications it would be worth
to use more specific APIs. Finally, the upcoming version of libjpeg-turbo also
brings a small performance bump worth pursuing.
Decoding Speed
The following plot shows decoding speed differences between our contenders,
as a function of the image quality.
Again, turbo is just much faster than vanilla libjpeg, using the ctypes wrapper is much faster than using opencv,
and using the newer version of turbo is worth it.
Three new candidates appear slightly on top of the speed ranking: turbo_beta_fast_dct, turbo_beta_fast_upsample
and turbo_beta_fast_fast. These activate options that trade higher speed for less accurate (or less visually pleasant)
approximations to decompression. They are deactivated by default in libjpeg-turbo, but other wrapper libraries,
notably tensorflow, do activate them by default under the premise that machine learning should not be affected by
the loss of accuracy. The same that our tests did not find any relevant difference on speed, they did not
show any elevated loss on visual perception scores, so we do not have any strong opinion on activating them or not,
we just think it is now mostly irrelevant.
Why is the ctypes wrapper faster than opencv? There probably are several reasons, but if one looks briefly
to the opencv implementation, a clear suspect arises. With libjpeg-turbo you can specify wich pixel format the
jpeg data is using (the jpeg standard is actually agnostic of which order do the color channels appear in the file)
to avoid unneeded color space conversions. OpenCV instead goes a long way to non-optionally convert between RGB and BGR,
probably to ensure that jpeg data is always RGB (which is a more common use) while uncompressed data is always BGR
(a contract for opencv). Add to this that opencv barely expose some of the features of libjpeg and it does not
have libjpeg-turbo specific bindings, our advice here would be to use a more specific wrapper to libjpeg-turbo.
Talking about wrappers, let's look at the last plot (for today). Here we show decoding speeds as a function
of image size.
The larger the image, the faster we decompress. This is normal: there is some work that needs to be done
before and after each decompression. The take home message here is, to our mind, to improve the wrappers to
minimize constant performance overheads they might introduce. An obvious improvement is to use an already allocated
(pinned if planning to use in GPUs) memory pool. This should prove beneficial, for example, when feeding minibatches
to deep learning algorithms. A more creative improvement would be to stack several images together and
compress them into the same jpeg buffer.
Note also that there are several features of turbo we have not explored here. An important example is support
for partial decoding (decode a region (crop) of an image without doing all the work to decode the whole image),
which was introduced in turbo recently (partially by google) and was then exposed in tensorflow. We have not actually
found ourselves in need for these advanced features, but let the need come, we are happy to know we have our backs
covered by a skilled community of people seeking our same goals: to get image compression and decompression times
out of our relevant bottlenecks equations.
Speeding Up Your Code
TLDR; use our opencv and libjpeg-turbo conda packages
So how do one use libjpeg-turbo?. Well, as we mentioned, libjpeg-turbo is everywhere
these days - so some software you run is probably already using it.
If you are using Firefox or Chrome to read this post, it is very likely that jpeg images are
being decompressed using turbo. If you use tensorflow to read your images, you are using turbo.
On many linux distributions libjpeg-turbo is either the default package or can be installed to replace
the vanilla libjpeg package. We are not very knowledgeable of what is the story with other platforms,
but we suspect that libjpeg-turbo reach and importance extends to practically any platform where jpeg
needs to be processed.
What if you use the conda package manager? In this case you might be a bit out of luck, because the two main
package repositories (defaults and conda-forge) have moved to exclusively use libjpeg 9b in their stack.
If you try to use a libjpeg-turbo package in a modern conda environment, chances are that you will bump
into severe (segfaulty) problems. This is a bit of a disappointment given that conda is commonly
used in the scientific, data analysis and machine learning fields these days.
But good news! if you are on linux your luck has changed - all you need to do is to use
our opencv and libjpeg-turbo packages (which bring along our ffmpeg package). Because
we use these packages in loopy we keep them in sync with the main conda channels and
ready to be used by any conda user.
These packages avoid problems with parallel installations of libjpeg 9 and libjpeg-turbo,
and offer other few goodies (like the ability to choose between GPL and non-GPL versions of ffmpeg or
patches to control video decoding threading when done via opencv). The creation of these modified packages
was not a small feature and will also be covered in a future blog post. In the meantime, you can just use
any of these command lines to use the packages:
# before running this, you need conda-forge in your channels
conda config --add channels conda-forge
# this would get you our latest packages
conda install -c loopbio libjpeg-turbo opencv
# this would get you and pin our current packages (N.B. requires conda 4.4+)
conda install 'loopbio::opencv=3.4.1=*_2''loopbio::libjpeg-turbo=1.5.90=noclob_prefixed_gcc48_0'
Or add something like this to your environment specifications (note these are the exact software
versions we used when benchmarking for this post):
name:jpegs-benchmarkchannels:-loopbio-conda-forge-defaultsdependencies:# uncomment any of these to get the opencv / turbo combo you want# note that, at the moment of writing, these pins are not always respected# see: https://github.com/conda/conda/issues/6385# opencv compiled against turbo 2.0beta1-loopbio::opencv=3.4.1=*_2# compiled against turbo 2.0beta1# opencv compiled against turbo 1.5.3# - loopbio::opencv=3.4.1=*_1# opencv compiled against libjpeg 9# - conda-forge::opencv=3.4.1# libjpeg-turbo 2.0beta1-loopbio::libjpeg-turbo=1.5.90=noclob_prefixed_gcc48_0# libjpeg-turbo 1.5.3# - loopbio::libjpeg-turbo=1.5.3
Finally, you can use these packages with our pyturbojpeg
fork to achieve better performance than generic libjpeg wrappers like PIL or opencv. If you
install both the turbo packages and our wrapper, you can easily compress and decompress
jpeg data like this:
Use the latest version of turbo and decide for yourself if using faster modes for encoding and decoding is worth it.
If you use conda then use our accelerated jpeg and opencv packages
We also think that any benchmark for, let's say, image minibatching for deep learning, should explicitly
include a solution based on libjpeg-turbo as a contender.
Finally, use turbo also if you do not need any of these things as it is very easy to install (on linux)
and will probably magically speed up many other things on your computer.
It is good to remember that open source software always needs a hand.
[1]
From the developers
libjpeg-turbo is currently under consideration for becoming an official ISO/ITU-T reference
implementation. Furthermore the libjpeg 'SmartScale' extension has not been adopted and
the likelihood of it being used even if it was - is low.
Video compression is polarising topic and a key technology
for us at Loopbio. In a series of blog posts, beginning with this one,
we put our didatic engineers hat on and share our experiences
on how to best leverage current compression technologies, with
a focus on practical benchmarking of video storage solutions,
ultimately seeking to find satisfactory trade offs between several
parameters: video quality, disk space and speed.
Part 1 (this one): an introduction to video compression for novices
Our company mission is to deliver best in class,
easy to use, video analysis solutions. For that we have created loopy,
a platform for working with arbitrarily large collections
of videos. It lets the users, from the comfort of their browsers,
explore, annotate and organize their videos. loopy
also offers state of the art analysis tools, from 3D vision
to deep-learning powered tracking.
To achieve our mission, loopy needs to be user friendly when used
interactively. It must also cleverly use possibly scarce hardware
resources, specially when running computationally intensive tasks. Our
infrastructure needs are also complicated by the fact that loopy is offered
in both an online subscription-based version, and an on-premise managed
server version.
Therefore, delays bringing video frames both to the browser and to the
analysis programs must be minimized. In particular, as we will see,
we should be able to accurately read from arbitrary video positions
in as little time and with as little computation as possible, and with
absolute accuracy.
A concise primer on video compression
Let us first start with a reading recommendation. This
introduction to digital video and references therein, which you
can read from the comfort of a gym machine - if you are into these
kind of things - is not to be missed. It contains an amazingly
visual description of the basics of video coding and related topics,
from the human visual system to codec-wars, touching on many of the
topics we will speak about in the next few paragraphs.
Basic terminology
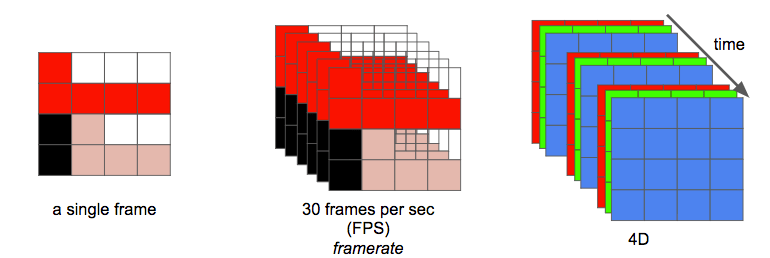
A video is just a sequence of images (frames), happening at a regular (generally but not required)
frequency in time (framerate), usually measured in frames per second
(FPS). When stored digitally, these images are usually composed of a
number of pixels, "dots with a color", organized in a grid.
The video has therefore a resolution that indicates the shape of
this grid, and which is usually indicated with width
(number of pixels per row) and height (number of pixels per column).
How colors are actually represented and their spectrum is given by
the so called color space. Each individual color is represented
by a number/(s) indicating the intensity of certain color components.
Videos have therefore also a color depth, that is measured in bits and indicates
how much information is needed to represent the color of a single pixel. Usual
color depths are 8 (for grayscale images), 24 (for "true color"
images) and 48 (for "deep color" images).
Compression
When stored digitally, an uncompressed video needs
`width * height * colordepth * framerate * duration` bits. How much
is that? As an example, one early video that a client uploaded
to loopy had a resolution of 1920x1080, 24 bits color depth and a
fast framerate of 120fps. If uncompressed, this video
would need 5 971 968 000 bits per second (this is know as bitrate).
In other words, a minute of such video would use up around 42GB,
or in other words, had we stored these videos raw, we could only
have been able to keep around 100 minutes. Our client has around 145
hours of beautiful fish schools footage recorded under the Red See, so
there is no way that would work.
Obviously no one uses raw video when storing or transmitting digital
video. Our client had around 145 hours of footage, but it was
taking only slightly less than 7TB (instead of 2835TB!). This is
so because the videos were compressed.
Video compression takes advantages of spatial redundancies (regions
of a single frame with a lot or repetition), temporal redundancies
(consecutive frames tend to look very much alike) and the human
visual perception particularities (for example, we can distinguish
better between bright and dark than between shades of colors) to
make storing and transmitting videos leaner, while still keeping
good video quality.
The two previous images (by courtesy of Simon Gingins)
are two consecutive frames from a video of the mentioned
collection. On each image the background is mostly blue
(spatial redundancy) and the difference between them
is minimal (if you can tell, fishes have moved slightly).
The programs that compress and uncompress videos are called
video codecs (a portmanteau of coder-decoder). While the techniques
used on each of them are highly related, there are many
different codecs with different characteristics. Different codecs may generate
larger or smaller videos, can compress and decompress at different
speeds and/or using different amount of computer resources, can allow
better or worse random access patterns, and can produce higher or lower
quality videos. In this series of blog posts, we will be interested in
finding out which video codecs are competitive, across many parameters,
to fill different roles inside our platform.
Compression quality
A very important distinction between codecs is the quality of the output
video, that is, how faithfully the compressed video represents the original
material. Codecs can trade size for quality. When aiming at reduced size,
codecs can use tricks that result in video artifacts. We probably are
all used to these kinds of obvious errors when, for example, viewing streaming
movies or looking at photos. While watching netflix, did you ever realized
how pixelated that super-red cape from SuperWoman looked like?
An important dividing line here is between lossless codecs, codecs
that ensure no loss of quality, and lossy codecs, codecs that do not make
such guarantee. Usually lossy codecs can be made to produce good quality video
(almost perceptually lossless) at a much higher space savings than lossless
codecs by exploiting the redundancies explained above.
Note: for this post and in general for this series, lossless codecs are assumed
to be operating under their native colorspace, we are thus ignoring any numerical effects
from colorspace conversion.
Lossless codecs receive much less mainstream attention than lossy ones, despite them
serving many important roles (in loopy and elsewhere).
For example, they are usually tasked with compressing video for archival or editing purposes.
We will in this series make lossless codecs an integral part of
our benchmarks, assessing how well they fare when compressing interesting
parts of larger video collections.
In particular, we will investigate their suitability when storing short annotated regions of
videos (clips) and frames (crops) for the purposes of batching/training a neural network for
object detection (discussed in a future post). In this workload, loopy needs
fast-access caches to concrete frames (in particular, frames that are annotated) in order
to feed them to our machine learning algorithms.
Types of frames and video seeking
A final video-codec concept we wish to introduce is that of frame type. As
we have said, video codecs can exploit intra-frame redundancy,
that is, pixel redundancy within the same image, and inter-frame redundancy,
that is, smooth changes between consecutive frames. Naively simplified,
inter-frame compression uses the difference between frames to encode
the video.
Videos compressed this way can contain up to three types of frames.
Intra frames (I) are self contained and can be decoded without refering to any
other frame. On the other hand, Predictive (P) frames require previous
frames to be decoded first, while Bi-directional predictive (B) frames require
both previous and posterior frames.
The main use for video is sequential playback. Modern video codecs can
employ quite complex combinations of I, P and B frames, and sort the data
for frames in an arbitrary order. Usually I frames are much less frequent,
because they consume more space. This is one of the reasons why seeking,
that is, reading an arbitrary frame from a video, is a slow operation. When
requesting an arbitrary frame, it is likely we will need to decode many other
frames to get the result.
To the best of our knowledge, there are no codecs that are specifically
designed for fast seeking (that is, fast random frame retrieval).
Seeking is a important operation for many tasks that loopy
needs to do routinely, so when too slow, it might affect negatively
the user experience. loopy often needs to display arbitrary
segments of a video, often accessed in a pseudo-random order (for deep learning
or by the user), with the video sometimes on slow underlying storage.
That is why we will also pay attention to seeking
performance of video codecs, which is not a topic usually covered
by video benchmarks.
Video collections at loopbio
Our company currently focus on servicing the life-sciences and,
in particular, the behavioral research community. Because of that,
we get to analyze some particular kinds of videos. The most common
video collection we help analyzing contains hours of high-resolution,
fast-framerate animal behavior recordings. Usually these come from
either still cameras - both in natural environments and behavioral arenas,
over and underwater - or aerial (drone) cameras. A recurrent characteristic
of these videos is a fairly constant background that, in many cases,
is also very simple.
We have expended a few fun minutes browsing youtube for publicly available
examples of these kind of videos, and have selected just a few:
We will be using these videos to illustrate a few concepts about video
compression and to benchmark video compression alternatives in later posts.
To finish on an inviting note, we will now show a couple of results from
our benchmarks on lossless codecs. We will provide codec descriptions
and describe in detail our benchmarking methodology in later installments
of this series.
Codec Selection Matters: Video Encoding Benchmark
How fast and how much do lossless codecs compress our benchmarking video suite?
We asked a few lossless codecs to re-compress the original videos at different
resolutions and we measured both quantities - disk savings and speed.
We summarize some of our findings in the following plot (click on the plot
legend to show/hide series):
A few codecs contend. ffv1, as we used it, is an intra-frame only
codec geared towards a good trade off between compression speed and space savings.
huffyuv/ffvhuff is a simple intra-frame only codec geared towards
fast decompression. We used ffmpeg to encode for both ffv1 and ffvhuff.
H.264 (encoded using ffmpeg bindings to libx264) is a fairly
sophisticated codec, with many nuts and bolts that can be tweaked
as needed; here we use its lossless mode. Each codec is parametrized
in different ways (see and click the legend).
We also include a lossy baseline - and it is quite a strong baseline - which will
serve as reference for speed during our benchmarks. We call it "exploded-jpg" and
it essentially works by storing the video by saving each frame individually
to a good quality jpeg-compressed file - so it is not a video-codec per se,
although there are codecs (mjpeg) that work in an analogous way.
Note the wide range of performances. In the vertical axis we plot the space saved
by compressing the video as a percentage of what would have taken to store it uncompressed.
Higher is better and so H.264 is the winner. In the horizontal axis we plot the
speed-up relative to the baseline. Again, the higher the better. So H.264, properly
parametrized, is a win win here. For an introduction to the operation of H.264, see this article.
Why do we have such broad error bars? A statistician would probably start thinking
about small data effects. While some of it might be true, here it does not really
tell the whole story, or even the most relevant part of the story. Instead,
this plot is a summary of writing workloads for different video types at different resolutions.
Codecs can behave quite differently depending on those conditions. To us,
these large error bars send this message: while having good defaults informed
by relevant data is important, sometimes it can repay to engineer for the
very particulars of an application. Obviously this is easier if one counts
with trustworthy benchmarking tools
An important note about the baseline speed. It is generally much slower
(2x to 4x) than the video codecs. Truth to be told, we did not parallelize it.
That is, while the video codecs were free to use as many resources from
our system as they wanted to - and all of them made the computer sweat a lot -
we only allowed the baseline to use 1 sad core. Note that, usually, parallelism needs to
be taken into account explicitly in a benchmark. When in the gym, I could
only read video compression tutorials when taking it easy over the
static bike. If I would work more intensely, then I would have lacked
the resources to also do anything else at the same time.
What we did use is for the baseline is a highly optimized JPEG codec.
This is too important to be overlooked, as we will discuss soon in this series.
While writing speed is very important for video acquisition systems
like our own Motif, for loopy writing speed only has a small relative
importance. For this reason, from now on we will focus our efforts on
thorough benchmarking "write-once, read-many times" workloads.
How slow is seeking with lossless codecs?
On our second and concluding for now result, we plotted
relative speed of retrieving a single random frame from a video
compressed with the codecs used above against the baseline.
Video codecs are, in the best case, an order of magnitude slower
when serving arbitrary video frames. This result holds no matter
the underlying storage system (let it be a SSD, a spin disk or
a network file system). That would immediately
disqualify them for many machine learning workloads, were a program
learns to perform some tasks by being exposed to examples
of such task in random order. Random data reading must be as much
as possible out of the way in a workload that contains many
other heavy computation components. Therefore,
the difference between a high and a low speed solution is
the difference between speedy result delivery and resource infra-utilization
leading to delays that can be counted in days or weeks.
Videos encoded as JPEG images, our baseline, is in fact the most
common way in which video training data is stored. We are
exploring if there is a way to use more efficient access patterns
so that video codecs can somehow become an option in this arena,
bringing some further benefits, like higher image quality,
better introspectability and web playability, with them.
See you soon
If you are interested in our comprehensive video reading benchmarks
follow us on twitter in @loopbiogmbh.
Conference season is here! If you are interested in seeing our
products or talking to us in person about your scientific needs
you can meet us at the following places.
Motif video recording software version 4.0 was released today. This version features many
changes and improvements, as demonstrated in the following youtube video
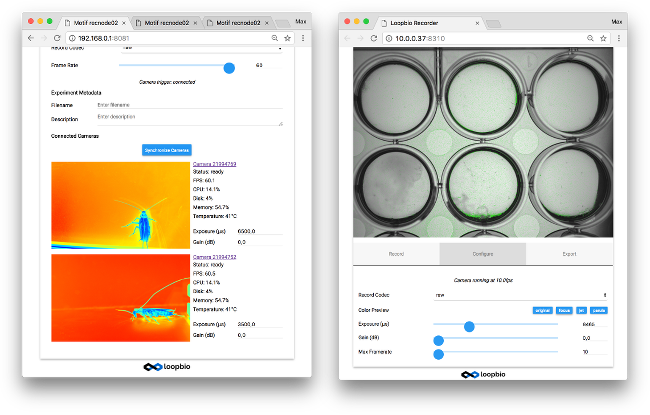
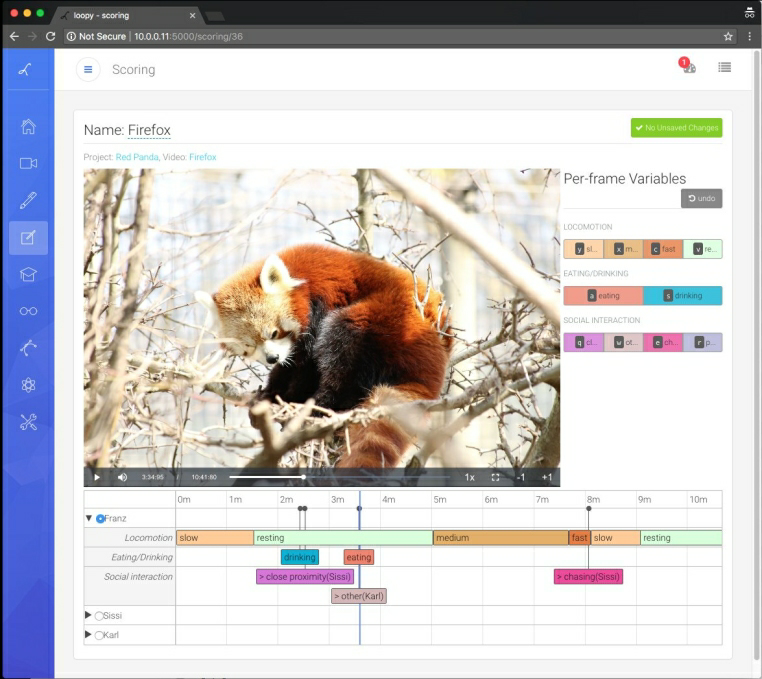
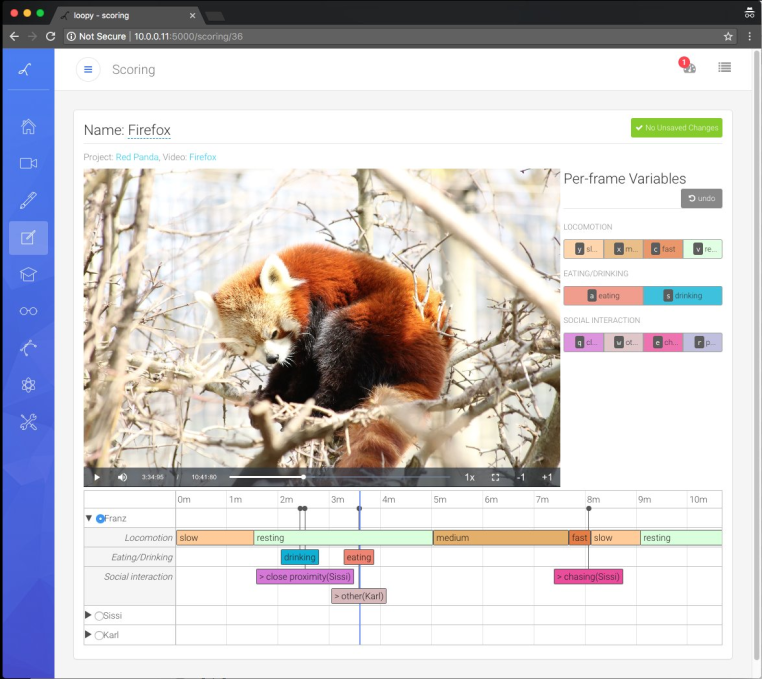
Motif is a video recording sytem which supports single single camera or multiple camera recording,
and video recordings can be from seconds to weeks in duration. The version 4.0 release has the
following highlights:
add zoom, focus feedback and colormaps to preview display
support multiple Ximea cameras
add 'delete after copy', i.e. 'Move' and 'delete after export' modes
add scheduler for scheduling recordings and other operations
Sample screenshots of Motif 4.0 multi-camera and single-camera web user interface
I'd like to demonstrate a the last two of these features using the new Python API.
Starting and stopping recording is easy. The following snippet demonstrates
starting recording on all cameras with the predefined compression settings
named 'high' (see the Web UI for the names of your configured compression formats). The
recording will run for 5 seconds and will have have the additional metadata 'experiment' and
'genotype' saved to the recorded file. The snipped works equally on single or
simultaenous multiple-camera systems.
Likewise, the API also supports defining scheduled tasks, this allows for example, to
schedule recordings and their subsequent copy to storage to occur at specific times. Task
scheduling re-uses Cron syntax with some extensions (monotonic tasks).
We are really excited about these new API feature as they allowa laboratory wide automation
of single or multiple recording systems or experimental assays. We are looking forward to
extending our API support in future releases.







.png)