Written on Tuesday July 02, 2019
Motif video recording software version 5.0 was released today. This version
features an enormous number of new features which continue to make Motif the
most capable and versatile solution for biologists looking to recording video
and other data from behavioural experiments.
Windows Support
This release adds support for running the Motif software on Windows 10. The user interface and
the available features are identical to when running the software on Linux.
I/O, DAQ, Sensor and Output Support
Motif already allows control of IO and reading of environmental sensors from within
the software, including support for the low cost phidget devices.
We now support the entire phidget range.
In Motif 5, I/O and DAQ support has improved to support more types of hardware, and control and
monitoring of configured IO has been improved throughout the software. Of particular
note are the following enhancements:
- Automatic synchronization of IO/DAQ signals with video data. Values of all configured input
in Motif will be stored with the recorded video (see information on our imgstore format),
including both the framenumber and timestamp of the video.
- Scheduled and manual control of configured outputs. Any changes to any defined IO/DAQ
output will also be saved in the recorded data (as above, in imgstore). This ensures
that not only are sensors able to be synchronized with recorded video,
but any stimulus changes (scheduled or manually set using the Motif API) are too.
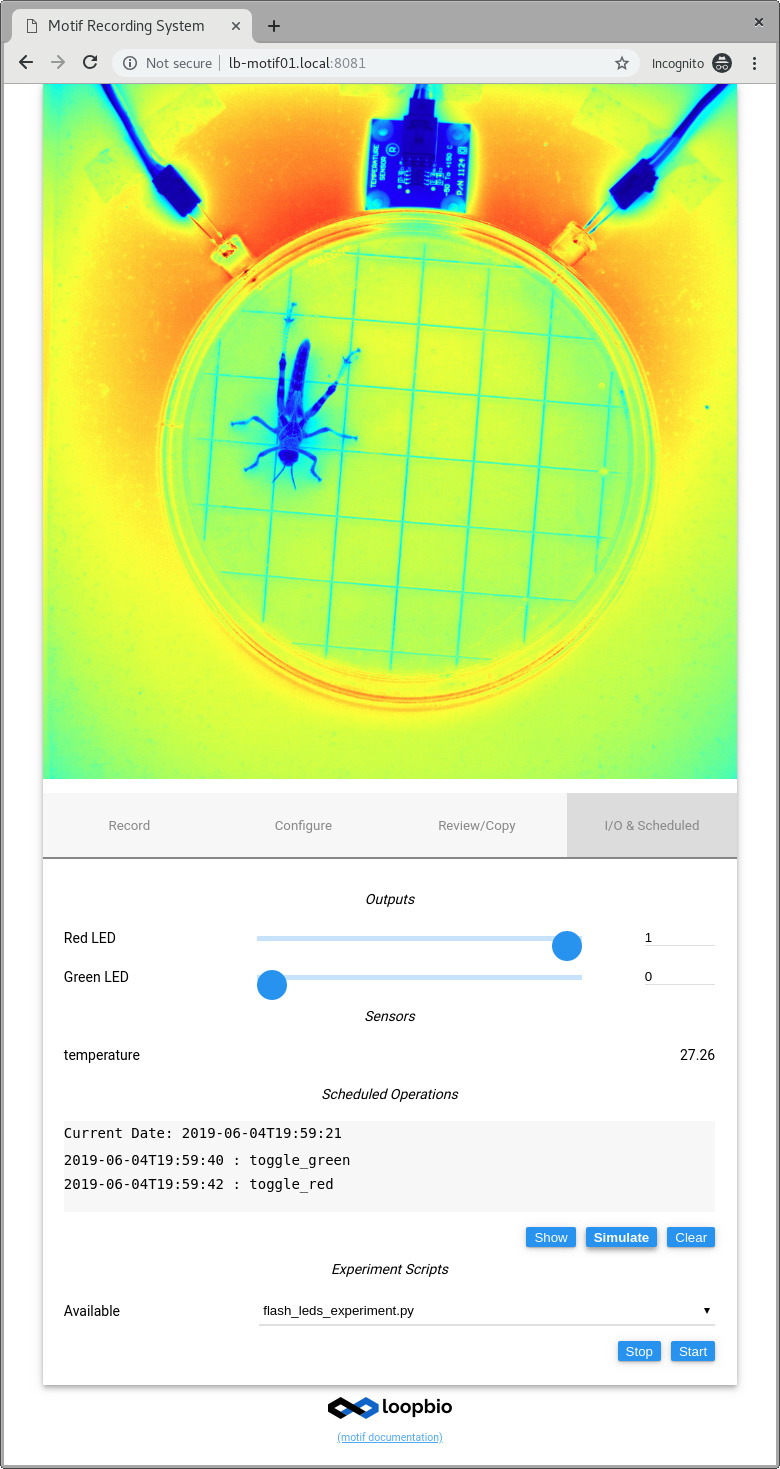
- Ability to manually control configured outputs in the user interface (see screenshot).
The current value of all configured inputs is also shown.
- IO signals can be set using the Motif API. They can be changed programatically, either
from experiment scripts or via the
scheduler function. Expected forthcoming scheduled changes to IO are now shown in
the UI (see screenshot)
- Support for other IO types, including certain National Instrument DAQs,
and control of IO over HTTP and ZMQ protocols
Experiment Scripts and Scripting Improvements
A major new feature is the improvement and integration of scripting and experimental scripts into
the user interface. Experiment scripts are written in Python (by default, MATLAB and other scripting
environments are also supported).
Users can define experimental scripts and then launch these from within Motif.
Scripts are placed in a platform-specific directory. These scripts can interact with Motif
using the Motif API in several ways:
- Scripts can operate in a one-time fashion, for example by setting up an experimental
protocol consisting of scheduled outputs and recordings.
For more experimental scripts which use the scheduler, see the
examples in the experiment script documentation
- Scripts can also run continuously, manipulating the Motif API in realtime
- Advanced scripts can even perform realtime image processing to implement closed
loop behavioural paradigms depending on the animal behaviour
Scripts placed in the appropriate directory are then shown in the user interface,
where they can be launched.
Scripts can be complicated
closed loop image processing operations,
collections of camera / imaging setting changes, or complete descriptions of experimental
protocols including recording time and duration, metadata, stimulus, and much more. For example,
the script below implements the following hypothetical experimental paradigm:
Record for 30 minutes, every-hour-on-the-hour between 6am and 4pm. While recording
alternately flash a red and blue LED every second.
from motifapi import MotifApi
api = MotifApi()
camera_serial = '22075785'
# initialize LEDs
api.call('io/led_red/set', value=0)
api.call('io/led_green/set', value=1)
# schedule recording
api.call('schedule/recording/start',
task_name='record_video',
cron_expression='0 6-16 * * * *',
duration=30*60)
# describe stimulus protocol (flash 'inf') LEDs
api.call('schedule/camera/%s/io/led_red/set' % camera_serial,
task_name='toggle_red',
cron_expression='%2 * * ? * * *',
camera_relative=True,
value=float('+inf'))
api.call('schedule/camera/%s/io/led_green/set' % camera_serial,
task_name='toggle_green',
cron_expression='%2 * * ? * * *',
camera_relative=True,
value=float('-inf'))
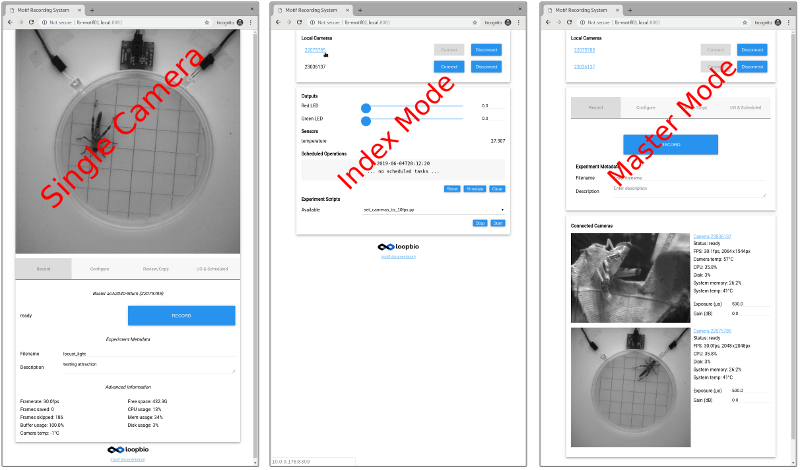
Improved User Interface
The user-interface has been polished and unified across the various modes of Motif operation:
single-camera mode, and the multiple camera 'master' and 'index' modes. Features which were
previously restricted to single camera interfaces (IO and timed recording) have been added
to the multicamera interface.
Live Image Streaming / Closed-loop Image Processing Support
Motif 5 adds the ability to, with very low latency (<1ms), stream realtime images
from the camera, without interfering with the recording, compression, or any other Motif
functions. This allows realtime image processing algorithms for closed loop experiments.
Such realtime algorithms can freely use the Motif API and thus, for example, provide
stimuli to the animal using configured Motif IO, or
user provided custom outputs.
We unveiled this feature at Göttingen Neuroscience Conference with the demo below: A
Motif system simultaneously records video and detects the position of the animal before
providing a stimulus illuminating LEDs underneath (using Motif IO). Motif saves not only
the video, but synchronized with it, the IO status too. From the saved data file Motif thus
allows easy analysis of behaviour and stimulus after the experiment.
If you are planning to perform closed loop experiments then consider Motif, it solves all the
saving, I/O, reliability, and synchronization problems for you.
Expanded Camera Range Support
This release adds support for cameras from FLIR (formerly Point Grey), extends
our support for Basler cameras, adds support for network cameras and standard
operating system supported cameras (v4l on Linux and UVC on Windows).
Extended Trigger and Synchronization Options
Motif 5 added support for a number of different trigger and synchronization scenarios
commonly necessary when synchronizing video recording with neurophysiology recording
or stimulation setups. This allows Motif to either take a variety of 'master' or 'slave' roles
with respect to the the triggering and recording of frames. Motif can consume trigger
pulses produced by other hardware, or generate a variety of different trigger pulses for
recording by the secondary neurophysiology hardware.
If you need video synchronized with neurophysiology, electrophysiology, or other hardware
devices then contact us to see what Motif can do for you.
Complete and Comprehensive Documentation
Comprehensive documentation is provided online and
is continually updated. Documentation explains the use and confiugraton of Motif, as well
as use of the Motif API and example experiment scripts.
Interested in Motif?
Motif is the first video and camera recording system designed for the experiments of modern
scientists. It supports single and multiple synchronized camera scenarios, remote operation,
high framerate and unlimited duration recording. It is always updated and has no single-user
or other usage limitations.
If you are interested in a Motif system, please contact us for a quote
or to see how Motif can solve your video recording needs.
Written on Monday February 25, 2019
Over the last couple of months we released a couple of interesting open source tools that might
be of use to some hackers out there. In typical bad-at-marketing-busy-company form we
then forgot to blog about them!
Stitchup is a python library for stitching multiple
videos together into a larger video mosaic or video panorama. This is a common scenario for users of
Motif video recording systems who have multiple-camera setups
to increase their spatial and temporal resolution.

Stitchup adds some functionality
(storing and loading of calibrations) and considerably improves upon the OpenCV in-tree
stitcher module Python API. Stitchup was used in the example above and for our previous
post on multi-camera high throughput c.elegans screening assay
Imgstore is a seekable and scalable for video frames and
metadata (see announcement and imgstore introduction here). Well,
we just released version 2.0
(and then 2.1, 2.2, and 2.3).
API compatibility was retained, however the 2.0 release features a few nice new features and
signifigant bugfixes
- Support for writing
h264 mp4 (.mkv) files was added
imgstore.align was added for aligning 'synchronizing' multiple simultaenously recorded
imgstores- Added utils for re-indexing stores around 0 and for other framenumber manipulation
- Many bug fixes
The new version can be installed from pypi using pip install -U imgstore.
Interested in Motif?
Motif is the first video and camera
recording system designed for the experiments of modern scientists. It supports single and
multiple synchronized camera scenarios, remote operation, high framerate and unlimited duration
recording. It is always updated and has no single-user or other usage limitations.
If you are interested in aMotif system, please contact us for a
quote or to see how Motif can solve your video recording needs.
Written on Monday January 07, 2019
2018 was a great year for loopbio! We continued to improve our products,
particularly Loopy image processing and tracking software,
and Motif video recording software, and our Virtual
Reality systems, to meet the needs of quantitative biologists around the world.
We are especially happy with the improvements and success of Loopy, which
left beta testing in January 2018 and grew in popularity rapidly - over the
course of 2018 Loopy was used:
- To help 149 scientists with their research
- To process 10577 videos (totalling 14.9TB of data)
- To track or analyze, using deep learning, 2D or
3D tracking, 3484 videos
- To annotate 2368 video segments
- To score 791 experiments
Let's review the year in order and highlight some of the moments we are most
proud of, including:
Loopy Is Born
At the turn of the year we launched Loopy to the general public,
making deep learning and 3D tracking available
to all scientists immediately, without having to write or maintain their
own software. Loopy can be used immediately by signing up at
https://app.loopb.io.
Loopy Grows Up
After Loopy's release, we didn't' stop adding features. We began by added scoring and behavioral
coding to Loopy, including social scoring.
We taught all our products - Loopy, Motif, and realtime 3D tracking
to get along with one another, demonstrating a world first at FENS conference: realtime marker free
pose tracking of mice (and other animals).
We added even more plotting and data analysis capabilities to Loopy - making it a complete
and integrated tool for analysis. Now you can create your own tracking solution,
including training your own deep learning based detector animal tracker,
upload and process videos, and plot and analyze data, without leaving your web browser.
We polished our complete suite of tools for 3D tracking, calibration and analysis.
Use your deep learning animal or pose detector for
3D reconstruction with ease!
Virtual Reality
We developed and delivered an innovative virtual reality system for flies.
We also delivered two FishVR systems to customers.
2018 was a great year for loopbio!
We wish everyone a happy new year and look forward to 2019!
Written on Wednesday October 17, 2018
We were approached by Andre Brown
to create a custom imaging setup for high-throughput worm screening. Dr. Brown and
his team are searching for novel neuroactive compounds using the nematode
C. elegans. He explained:
"To screen a large number of drugs, it helps to image many worms
in multiwell plates. Normal plate scanning microscopes don't help because
we want to see behaviour changes that require looking at each worm for
minutes so we have to image the worms in parallel. At the same time, we
need enough resolution to extract a detailed behavioural fingerprint using
Tierpsy Tracker.
A six-camera array provides the pixel density and frame rate we need
and opens the door to phenotypic screens for complex behaviours at an
unprecedented scale."
The Solution
To meet the requirements we designed a solution using 6x 12 Megapixel cameras
at 25 frames per second. To save on storage space, all video is compressed in
real-time, at exceptional quality, before being saved to disk. The flexibility
of Motif allows synchronized recording from all cameras, controlled from a
single web-based user interface.
For an impression of the images possible with such a system, check out
the interactive (mouse over / touch for zoom controls) viewer below.
unfortunately the generation of the visualisation above introducted some
artifacts not present in the orignal video
Interested in Motif?
Motif is the first video and camera recording system designed for the
experiments of modern scientists. It supports single and multiple synchronized
camera scenarios, remote operation, high framerate and unlimited duration
recording. It is always updated and has no single-user or other usage limitations.
If you are interested in a Motif system, please contact us for a
quote or to see how Motif can solve your video recording needs.
Written on Thursday October 04, 2018
We are happy to announce that loopbio gmbh has been accepted into the
NVIDIA Inception Program.
The program is designed to nurture dedicated and exceptional
startups who are revolutionizing industries with AI and data science.
The Inception Program provides direct access to NVIDIA's latest technology,
deep learning expertise, and a global network of partners and customers.
Loopbio was the first company to bring easy to use deep learning based video analysis and
tracking soulutions to the quantitative and behavioural biology research fields. Our
revolutionary loopy product was launched in 2017 and allowed AI tracking and
analysis of animal behaviour, using only your web browser and without writing any code.
Loopy has been improved ever since with the addition of state of the art
AI algorithms for pose and 3D tracking, and image and behavioural classification.

Unlike other AI platforms, loopy does not stop at just model training. It provides
comprehensive tools for performing quantitative analysis on processed video to let users
get high quality scientific data faster.
About Loopbio
Loopbio was founded in 2016 to bring cutting edge technology to
behavioural biology. The company is based in Vienna and provides integrated solutions for high-speed
single- and multiple-camera video recording, video analysis and tracking, and virtual reality.
Written on Tuesday August 28, 2018
Following the last release we have continued to add features
and improvements to our Motif software. This post includes a short overview of some hightlights,
while a full list of changes is provided on our website.
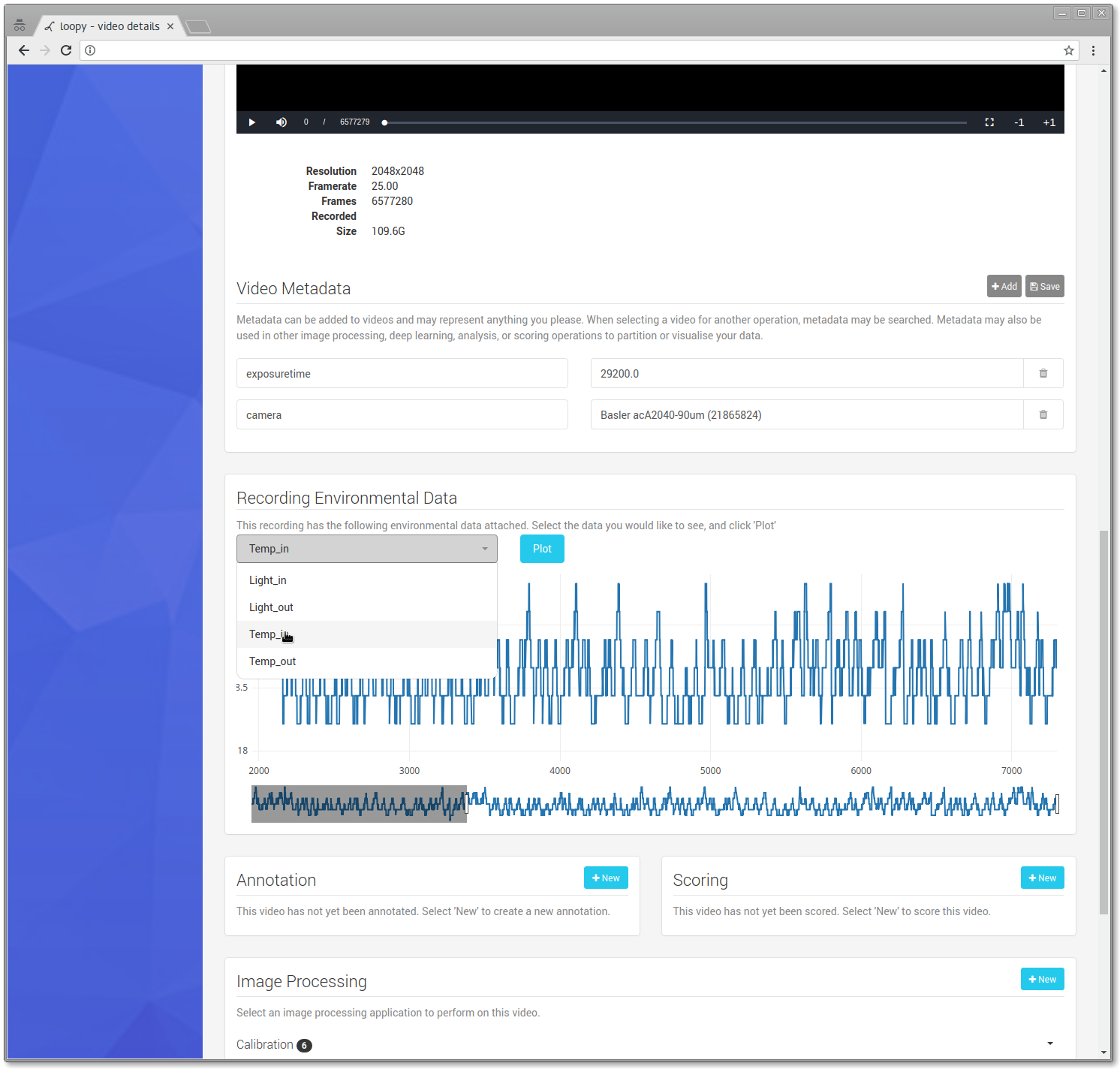
Each and every Motif system receives automatic updates without any extra charge.
Increased Support for Environmental Sensors
We have improved our support for environmental sensors from Phidgets greatly. This means that
you can simply connect any one of their 'VINT' series sensors to a Motif system and
you can now take sensor recordings automatically, at several different sample rates. Phidgets
offer an enormous variety of sensors which can be used to measure various parameters of your
experiment while recording video, including;
Because we record to our extensible and open imgstore format,
all sensor recordings are immediately associated with both the time and framenumber of the video
being recorded.
Controlling Outputs
In addition to measuring environmental sensors, we added the ability to switch on or off supported
Phidgets outputs, relays and motors. Using our open API
you can now, for example, perform tasks like the following
- control experimental stimuli at regular or scheduled times
- control physical devices such as motors, servos or actuators
- switch on/off LEDs, lights or other stimuli
- schedule tasks for before or after recording has been completed, such as automated
feeding or cleaning procedures
Improved Integration with Loopy
Following on from above, if you have a recording with environmental data associated, this
will be immediately visible in Loopy after the imgstore has been uploading or imported.
Automatic Import
If you are running an on-site version of Loopy, your Motif and Loopy systems can be configured
to allow automatic import of recordings after the completion of your experiment. This feature
is especially advantageous when both systems are integrated with your IT infrastructure because
all video and experimental data is automatically added to your shared and backed-up network
storage without risk of deletion or loss.
Further descriptions of the powerful integrations between Motif and Loopy will be the subject
of a future blog post.
New Alignment Visualization
The last motif release added a number of image feedback augmentations to
help with setting up your cameras and experimental assays. This release added a new visualization
designed to help with alignment of samples inside the experimental apparatus, or to help
align multiple cameras in a multiple-camera situation.
Interested in Motif?
Motif is the first video and camera recording system designed for the experiments of modern
scientists. It supports single and multiple synchronized camera scenarios, remote operation,
high framerate and unlimited duration recording. It is always updated and has no single-user
or other usage limitations.
If you are interested in a Motif system, please contact us for a quote
or to see how Motif can solve your video recording needs.