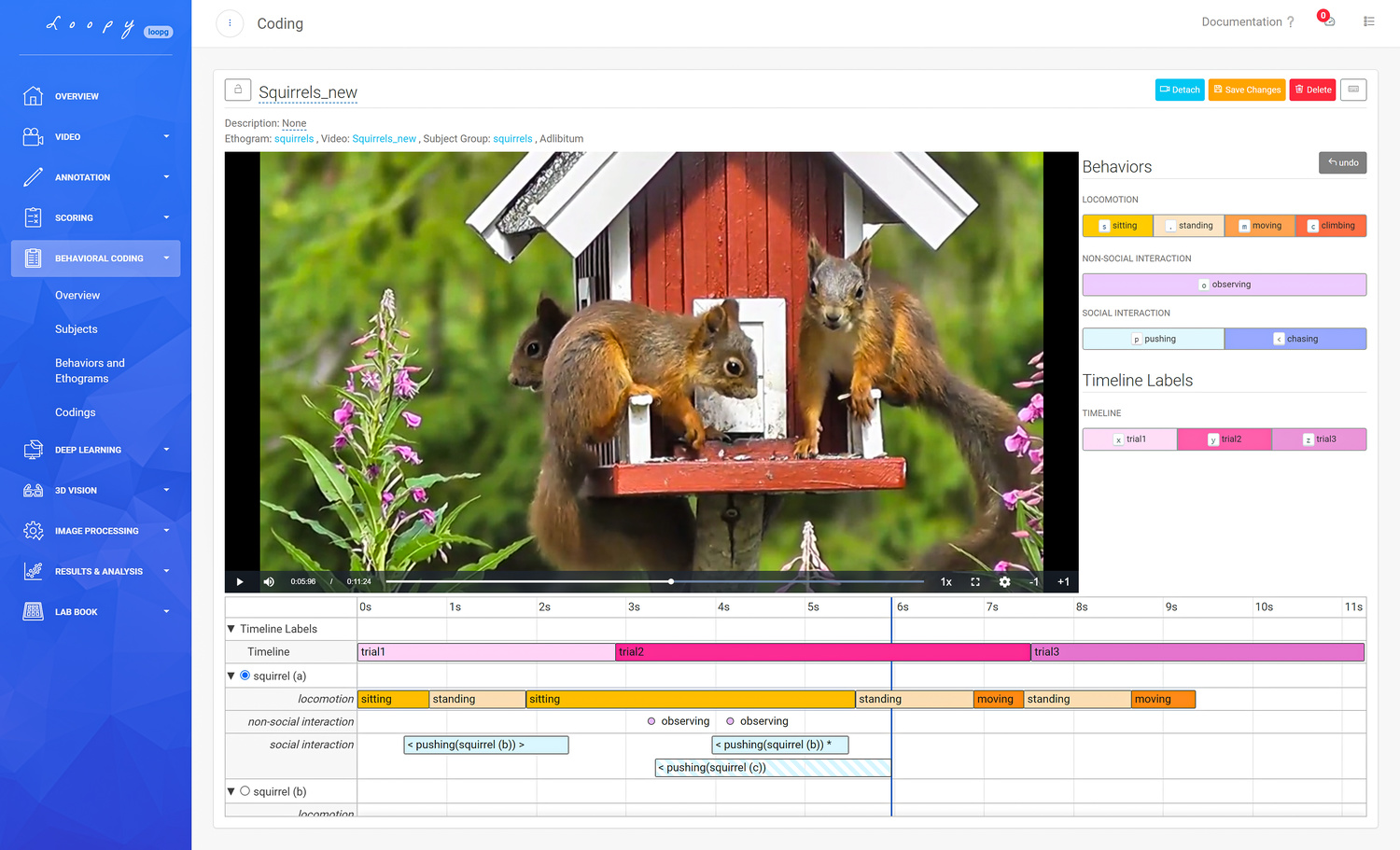
Animal behavior is a broad scientific field and a topic of many research questions. Loopy’s Behavioral Coding tool allows interactive coding of behaviors on a video timeline from your web browser, with no software to install.
Loopy’s Behavioral Coding tool.
We are proud to introduce the second major version of the Behavioral Coding tool, the result of many years of development and consultation with our customers. We have reorganized the structure of our tool to better reflect how multiple scientists collaborate on research that uses behavioral coding.
The key word to describe the Behavioral Coding tool is "composability". The components of a coding project; for example, Subject(s), Behaviors, and Behavior Categories are now concepts that can easily be shared between Ethograms.
This means that one can now define Subjects and Behaviors in one place and then re-use these in multiple Ethograms, which saves time, and allows robust comparison of Subjects and Behaviors across different Ethograms, shared by different scientists.
We have also added two new often-requested features; Modifiers and Timeline Variables. Modifiers allow one to further describe a Behavior at the point it occurs - such as modifying the "running" behavior with "fast" or "slow". Timeline Variables allow segmentation of videos into multiple phases, and analysis of distinct behaviors occurring only in certain phases - such as "acclimatization" and "trial" phases of a video.
A video coded with Loopy showcasing our newest features (Modifiers and Timeline Labels).
All these components are then composed into an Ethogram to be used to code a video. The details are outlined in the schematic below.
A schematic of the different elements included in Loopy’s Behavioral Coding tool.
If you are curious, keep reading to learn more about Loopy’s Coding tool and how to set everything up.
Loppy offers a free trial, click HERE to sign up now!
Start with a Subject and Subject Group
Subjects are set up to uniquely identify your test animals, like in our example, squirrels (e.g. "squirrel (a), squirrel (b), squirrel (c)").
How to create a Subject and a Subject Group.
Any of these Subjects can belong to a very specific (e.g. "Squirrel family A") or more general (e.g. "treated squirrels") Subject Group.
Behaviors and Behavior Categories
Use Behaviors to describe certain freely defined actions of interest (e.g. "feeding", "eating", "running", "chasing"). Behaviors are performed by Subjects and can be set up as Durations ("standing") or punctual Events ("observing"), both of which can be further defined as Non-social or Social. A Duration has a start and an end, while an Event is a single point in time and has no duration.
Examples of Durations and Events.
Multiple Behaviors can be grouped into Behavior Categories (e.g. "climbing", "standing" and "running" into a category "Locomotion") which will make them mutually exclusive - that means that only one Behavior can be active at a time. Multiple Behavior Categories can then be used as building blocks to assemble an Ethogram.
Importantly, Events and Durations, and Social and Non-Social Behaviours can not be mixed within the same Behavior Category.
Creating a new Behavior and Behavior Category.
Assembling It All Together - Ethograms
Ethograms represent all Behaviors and their features that you want to code. They combine Behaviors, Behavior Categories, Modifiers (see below), Timeline Labels (see below), and your Codings (videos ceded with this Ethogram).
An Ethogram with multiple Behaviours in multiple Behaviour Categories, Timeline Labels, Modifiers and keyboard shortcuts.
You can personalize the color of each Behavior and the keyboard shortcut you want to use, to make coding even more efficient.
Create your own Keyboard Shortcuts.
The same Ethogram can be used for coding multiple Videos.
Coding a Video
A Coding is the combination of an Ethogram, a Subject Group, and a Video allowing you to code your defined Behaviors.
Creating a new Coding.
You can decide between an Adlibitum (default) coding, where all Subjects of a Subject Group have their own timeline (you can code Behaviors for all Subjects in parallel), or Focal Subject (optional), where only the selected Subject has a timeline (you can only code this Subject). For Social Behaviors always all other subjects of that Subject Group will be shown and available for selection (this is also true for using a Focal Subject).
Code Durations and Events.
Social Interactions
Social Behaviour can easily be included in your Coding using Loopy’s Behavioral Coding tool. You can assign partner Subjects and record the directions of each coded Behaviour (as "emitting", "neutral" or "receiving"). Social Durations have a start and end points, at each of which the direction can be defined. This allows capturing behaviors like "monkey (b) starts to groom monkey (a) and after some time monkey (a) ends being groomed by monkey (b)". In comparison, for Social Events - which exist at a single point in time only - only one direction can be defined.
Coding social interactions.
The Focal Subject can have as many instances of a Social Behavior active as Partner Subjects are available.
Coding a Social Duration Behavior Category with two Behaviors (laying together, sitting together) for the Focal Subject "squirrel (a)" with its two partners "squirrel (b)" and "squirrel (c)".
New Features
Modifiers
Modifiers are a great new feature of the Behavior Coding tool. They allow more dynamic use of Behaviours by adding another level of configurability. The same Modifiers can be added to multiple Behaviors, for example, "together", "alone", "fast", and "slow".
Define the Modifiers you want to use in your coding.
Multiple Modifiers can be added to the same Behaviours. For each of your Ethograms, you can choose which Modifier fits best.
Coding a Duration Behavior with Modifiers.
Code including your Modifiers.
You can also combine social interactions with Modifiers for even more precise coding.
Coding a social interaction with Modifiers.
Timeline Labels
Timeline Labels are also a new feature in the Behaviour Coding tool. They allow you to organize video segments. They can be used to define different phases of your coding, for example, "acclimatization", "trial 1", "trial 2", "rest" or "experiment 1", "experiment 2" "experiment n" i ncase you have a multiple experiments in one video
Using Timeline Labels for organizing video segments.
Plot and Download Data
Loopy allows you to download the entire raw data of all Codings to apply your specific analysis. Additionally, Loopy can plot and display Ethograms and Summary Statistics.
Plots and Downloading data.
Loopy also allows you to specifically select certain segments of your data for analysis. You can either select individual Codings, or all Codings of an Ethogram, and you can download the data in multiple formats.
Plot your data as a Behavior Ethogram.
Care to try Loopy yourself?
Click HERE to sign up for a free trial today!
Researching motion patterns can be time-consuming, especially if you
have to track a lot of similar-looking body parts like the segments of
worms, the spine of a fish or, what I show below, the tergits of
centipedes manually.
Multiple skeleton-tracked Scolopendra oraniensis.
Luckily there is a way to overcome these problems. Using the deep
learning-based Keypoint detector from Loopy saves a lot of time and
energy by not having to manually track the animal or body parts frame by
frame. You manually annotate the points you are interested in manually
in a few images and Loopy will train an optimal model for you - you
don’t need expensive hardware or any programming skill for that as all
is happening on the Loopy server. The resulting model will locate the
animal or the different body parts, depending on your research question.
Sign up for a free trial for
Loopy today and feel free
reaching out to me if you have any questions (christina@loopbio.com).
In parallel to my work at Loopbio I’m working as a member of a
research team (Valentin Blüml, MSc; Christina Kaurin, MSc; Dr. Andy
Sombke) at the University of Vienna. We are trying to discover the
underlying mechanisms of myriapod locomotion in the Scolopendromorph,
Scolopendra oraniensis, by using Loopy. Our main interest lies in the
correlations between body undulation and speed, as well as the function
and movement of specific legs.
There are few old studies describing the locomotive gait of
Scolopendromorphs. Methodically these are limited due to the lack of
high-speed cinematography and modern data analysis techniques available
when they were performed. However, in the past years, the boom in AI
technology and improved video recording
hardware has made the advanced analysis of myriapods locomotion feasible.
Manual video tracking would have been an insurmountable amount of work
but new machine learning technologies, such as those provided in
Loopy, make tracking of segments, legs and antennae possible within
days or hours.
A little bit of self-promotion: The advantage of Loopy compared to other
toolkits out there is that you use it from within your browser. You
don’t need to instal anything or have fancy hardware, all the heavy
lifting is done on our servers. Sign up for a
free trial , upload a
video, start annotating a bit and train a model within minutes.
High Speed Locomotion
When moving at higher speed a greater body undulation should be visible
as this would act to increase the step size.
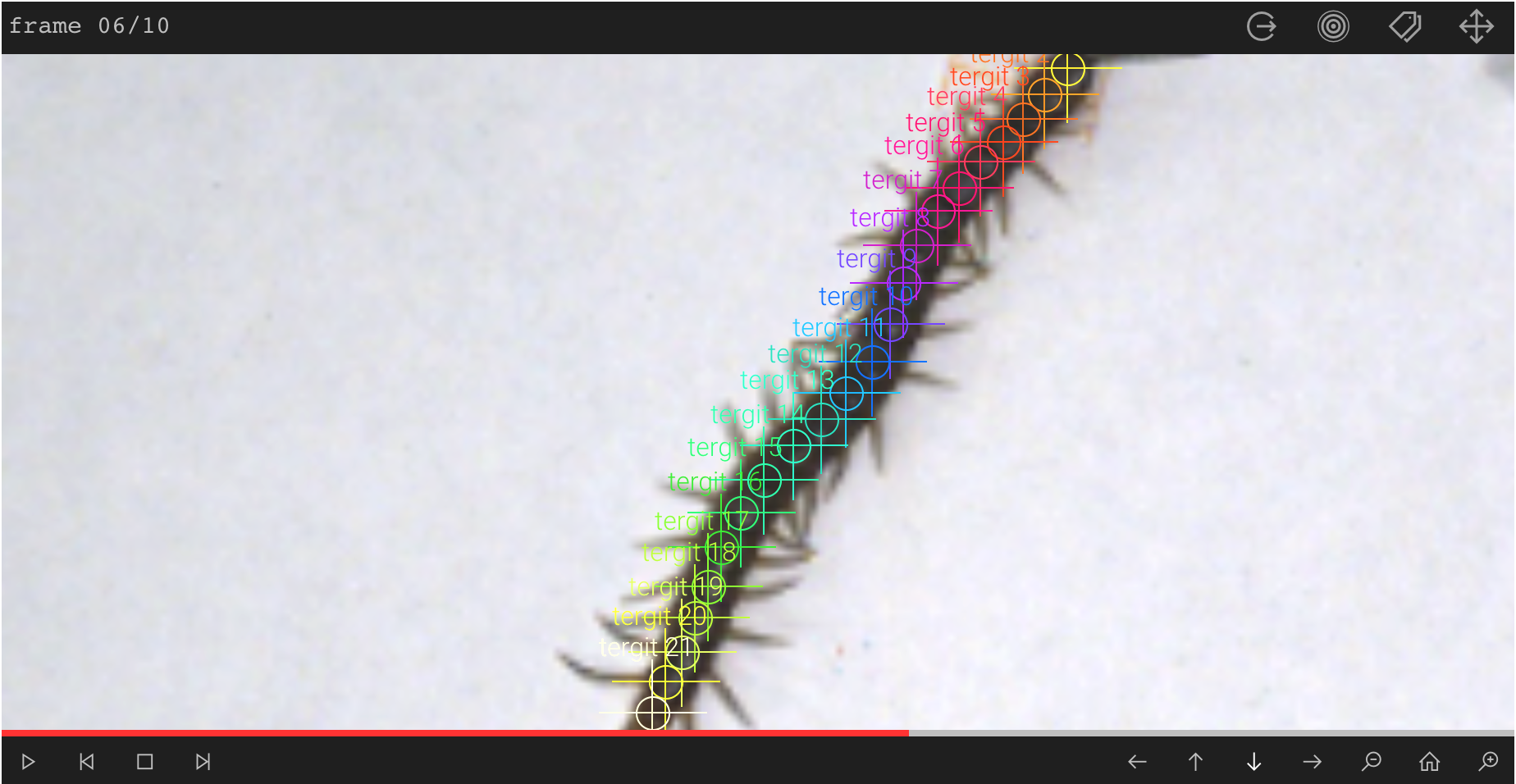
To correlate body undulation and speed the head and 21 tergits of 14
individuals have been tracked with Loopy's deep learning-based
pose-tracking module. Tracking manually would have been time-consuming
and practically impossible, because of the amount of similar-looking
body parts. After annotating some images I started training some models
in parallel with permutations of the few training parameters. Loopy
started to pick up the identity of the individual body segments reliably
after about 300 images being annotated. To reduce false negatives and to
increase the precision of detection I decided to annotate some more
images by setting the markers at the center of the head and each tergit.
The determination of any other position would have been way too
difficult and thereby too imprecise.
Annotating the individual tergits to train the skeleton tracking deep learning model.
Automatic tracking of individual segments by their identity works very reliably now.
We are currently looking into the actual kinematic motion data and we hope to publish
our findings soon.
Function and Movement of specific Legs
The last few leg pairs can be a bit special in terms of locomotion so we wanted
to look at these with the help of keypoint tracking as well. In contrast to the
running legs the last pair of legs (ultimate legs) is facing posterior and thereby
does not participate in locomotion. In different taxa they may have different functions,
like for example defense, to threaten possible predators, or to hold onto different
surfaces, like the ceiling of a cave to catch prey.
Videos have shown that not only the last, but also the penultimate pair of legs
often aren’t used for walking, but are dragged, especially when the animals are moving
slowly. So perhaps there is a correlation between the movement of the 20th pair of
legs and the speed of the locomotion.
To test these observations the last 3 pairs of legs and the antenna were
tracked. Our study is far from being finished but we are confident that
our hypothesis will hold.
Without Loopy it would have taken a significant amount of time to
track each tergit, the antenna and the different pairs of legs if it
would have been possible at all. Studies like this show that machine
learning-based programs gain more and more importance in today’s
research and thereby make the impossible possible.
2020 was a unique year for everyone, and Loopbio was no different. To meet the needs of this new normal, we continued to extend and improve our products and are especially encouraged by how diversely they were used by scientists in homes and labs around the world.
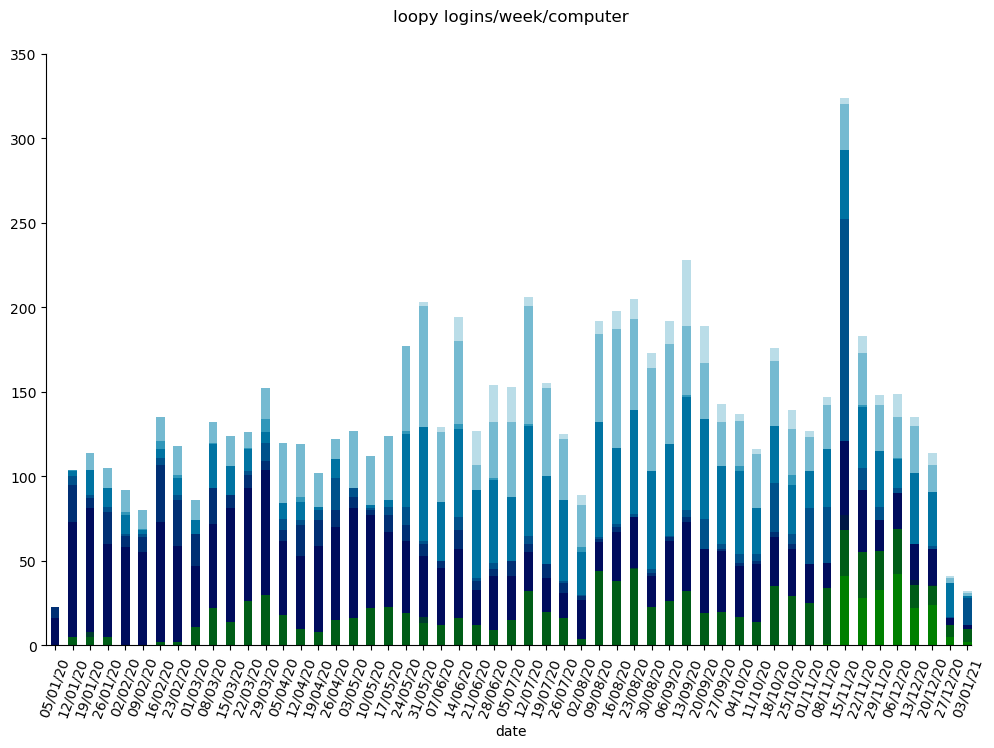
The popularity of Loopy is continuously growing, with its use doubling over the previous year.
Because Loopy is web based, it can be used from anywhere - a perfect tool for working from home during the various lockdowns and closures. The integrated group feature helped sharing data quickly between lab members and allowed collaborative analysis in real time - minimizing the loss of productivity from remote work.
In the figure below which shows the total number of users logging into Loopy (pooled across all online and on-site systems in all countries) you can see small effects of the first and second lockdows, but the strongest effect is the Christmas break - it seems everyone really needed a rest this year.
Loopy usage across all instances throughout the year
Let's review the year in order and highlight some of the moments we are most proud of:
Due to the pandemic the working life of many people changed and home office started to play a major role in our everyday lives. To support the increasing use of Loopy online (seen in the graph above) we decided to add more computers and GPUs to our loopy cloud to support those who are working on tracking, analysis, or deep-learning from home all around the world.
— loopbio quantitative biology (@loopbiogmbh) March 13, 2020
Loopy on-site https://t.co/N7kJ6FiwWP is shared video tracking, coding, deep learning, & video processing infrastructure for the whole lab/group. Data remains secure on your storage, multiple users can work at once & #workfromhome. Below, a new 🖥️ system already heavily used 🔥🔥 pic.twitter.com/QqPgt8OqO4
— loopbio quantitative biology (@loopbiogmbh) June 4, 2020
Loopy Continues to Improve
Throughout the year we didn’t stop working on Loopy - adding new features and updating the Software. The new features are immediately available to all existing users for free.
We improved the search feature by adding the ability to look for videos based on tags, labels and projects. By making it easier to navigate data, Loopy works better in large collaborative environments, such as when a loopy on-site server is shared by different research groups within a department - with all users uploading, processing yet working from home as was seen this year.
Another powerful new feature recently added to loopy; structured search, query (and saving) of videos and metadata. As more departments move to loopy, we have improved the ability to search videos based on tags, labels and projects ('lab book' feature: https://t.co/4SvGUCe7pB) pic.twitter.com/PSWyrFiC4c
— loopbio quantitative biology (@loopbiogmbh) May 26, 2020
We added a lot of new audio and video processing functionality in Loopy. This included the generation of audio spectrograms, animated amplitude histograms and more. These can be used when scoring videos,
allowing for mixed visual-audio scoring.
A lot of new audio+video processing functionality in loopy lately, including the generation of audio spectrograms, animated amplitude histograms, etc. Resulting videos can be used for deep learning classification and for mixed audio+video coding. https://t.co/c2rYR0nJ9kpic.twitter.com/ZQitMMIVEf
— loopbio quantitative biology (@loopbiogmbh) May 20, 2020
Research on locusts received well-deserved attention in 2020 as huge locust swarms devastating Africa and Asia emerged. Answers on how such swarms emerge and what can break them apart are urgently needed. Several televised documentaries throughout the year featured the research done with the help of our locust virtual reality system to help answer these questions.
Missed our LocustVR announcement or the Locust documentary? We've added a short video to the case study of this world first virtual reality system https://t.co/IXE2qQDUxDpic.twitter.com/7fl6RDqekD
We extended the specifications of Kastl based on customer feedback. These included extending
the specifications to meet the needs of scientists wanting high-throughput methods to study small animals with optional support of optogenetics and other automation possibilities.
We also improved our range of cameras and lenses for Motif. In particular due to the increasing
number of customers requesting multi-camera synchronized systems for 3D tracking.
— loopbio quantitative biology (@loopbiogmbh) July 27, 2020
Imaging Encyclopedia
Recently we released the Imaging Encyclopedia which describes how technical and operational aspects such as lighting, camera adjustment and scene composition are important for image quality.
With the Imaging Encyclopedia, we hope to help our customers as well as everybody who is interested in working with cameras, lenses and lighting to collect good quality imaging and video data. We continue to extend the Imaging Encyclopedia constantly, so check in every once in a while, and feel free to suggest more topics that we should cover.
If you work with cameras, lenses or lighting you might be interested in our new Imaging Encyclopedia https://t.co/wH9VGz7JQD - A comprehensive guide on how to collect good scientific quality video data 🎥🐟🦗🪰🧫🪱 pic.twitter.com/hYqIiwm5cN
2020 was a big year for loopbio! We are looking forward to an even better 2021! Please consider following us on Twitter
and feel free to contact us at any time.
Recording multiple subjects at once when performing behavioral screening or study is a great way to increase the sample size in a scientifically rigorous fashion - because the recordings are simultaneous and at the same location, environmental and external influences can be kept constant.
Grid structures forming compartments, such as multi-well plates but also much larger structures for open field research are regularly used for high-throughput behavioral video recording and tracking of C.elegans, Drosophila, Zebra Fish, Mice, Rats and many other species.
Imaging an array of compartments with a single overhead camera is often the preferred solution. However, using a single overhead camera to acquire video data of multiple compartments separated by walls can be challenging. This challenge persists for areas of all dimensions and scales, from a multiwell plate to an arena measuring several square meters. Nevertheless by following good optical design and imaging principles the quality of your raw data can be maximized. This post describes some of the relevant principles.
Loopbio have built and delivered systems like these described below. If you are interested in one of the systems below, or if you have special requirements please contact us now!
An example system with lighting (visual and/or near infrared) for recording 108 compartments.
The view of an overhead camera is obstructed by walls dividing the total area into compartments. The walls obstruct direct line of sight and cast a blind area. This problem exists at every scale - detection and tracking of subjects, be it very small C.elegans or much larger fish will not be possible in the obstructed area or volume.
Blind spots will be present in all configurations where a single camera records many compartments
How to Minimize Blind Spots
The distance of the camera in relation to the width or diagonal of the area is the most important factor. The closer the camera is to the arena the more significant this effect will be. Positioning the camera at a greater distance from the compartments will reduce the size of the blind area. This is because the "Angle of view" is smaller and consequently the light rays become "more parallel" compared to the camera being close.
A comparison of camera-rays when mounted close to or far from the compartments. Cameras mounted close to compartments cast larger blind areas whereas cameras mounted further away from compartments reduces blind areas
The second factor influencing the size of the blind area is the height of the walls. The higher the walls are the larger the blind area will be. Reducing the height of the walls separating the compartments will reduce the size of the blind area.
What If Distance and Compartment Height is Fixed?
Changing the wall height of a cell culture plate (multi-well plate) is possible but often not feasible. This is similarly true when working with larger off the shelf compartments for fish, mice, or similarly sized model organisms. Increasing the distance between the camera and the compartments might be limited by the height of the ceiling of the room, the height of the incubator, or maybe the height of the rack everything needs to fit into. Several options mitigate this limitation or eradicate it at all.
Using Multiple Cameras
Using multiple cameras, each with a smaller angle of view can be used for reducing the blind area significantly.
Multiple cameras viewing subsections of an arena reduces the size of the blind area and can be used for increasing spatial resolution and frame rate
Increasing the number of cameras for a given area simultaneously reduces the blind area but also allows for increased spatial resolution and framerate.
Motif Recording Systems for multiple cameras are a common configuration.Kastl-HighRes (High Resolution Multiple-Camera System) is a good example of using multiple cameras (up to 6 cameras) for reducing the blind area in a multi-well plate configuration with an extremely high resolution of 75 to 100pixels per mm across the whole multiwell plate at up to 30 frames per second. For more information on systems of this nature please see our case study here.
A similar use of multi-camera arrays is to cover a larger area without compartments. This is a common application if either higher resolution and frame rates are required than what a single camera could provide, or if the height of a system is limited. Continue reading our case study about Video Recording of Fish Assays.
Increasing Camera Distance with Mirrors
One or multiple mirrors can be used for increasing the distance between the camera and the compartments even further. Using a good mirror - preferably a surface mirror - allows maintaining the quality of the image. Precise mounting of the mirror is of essential importance. If a mirror or the camera moves the perspective on the arena will move as well. Slight changes in the angles might result in a large effect.
Increasing the distance between the compartments and the camera can be achieved with mirror arrangements
Collimation Lens
If the walls are relatively high, the space above the arena is limited or using multiple cameras is no option, an additional optical component, a collimator lens (fresnel lens) can be considered. Such a lens collects an orthographic view of the arena reducing or even eliminating blind spots.
This arrangement can also remove perspective distortion that makes further objects appear visually smaller (e.g. a fish in a fish tank being at the surface or bottom of a tank will then have the same size in the image). Such lenses are quite thin (2-5mm), lightweight, and very cost-efficient.
A large disadvantage of such lenses is that they reduce the sharpness and resolution of the resulting image and are therefore not applicable for high-resolution applications. In addition direct lighting from the top will be harder to realize. For high-resolution applications, a telecentric lens (see below) could be an alternative.
Loopbio has evaluated numerous collimation fresnel lenses available on the market and can suggest the best lens for your constraints. Through our relationship with fresnel lens manufacturers we can even provide custom lenses for your geometry. For more information and the maximal size of an arena please contact Loopbio
Telecentric Lens
Telecentric lenses only accept light rays parallel to the principal axis of the lens creating an orthographic view of the arena - an image without perspective distortion. This is similar to an arrangement with a fresnel lens (see "Collimation lens" above). Apart from their extraordinary visual quality, Telecentric lenses are quite heavy (up to several kilograms), physically large (the diameter needs to be larger than the diameter of the arena), and also very expensive (several thousand euros). Telecentric lenses work best with telecentric illumination.
A representative telecentric lens attached to a camera captures an orthographic view of the arena.
For example, to image an area of 2 multiwell plates (190x124mm) a telecentric lens with a length of 775mm and a mass of >20kg is required. The whole assembly measures would measure ~1340 mm in height. For imaging a single multiwell plate (124x84mm) a telecentric lens with a length of 430mm and a mass of >5.5kg would be necessary, the whole assembly would then measures ~1000 mm in height.
A Moving Camera
If the simultaneous recording of all compartments is not required one can consider moving the camera with a gantry system. Such a system, be it 1 or 2 axes, can move a single camera to multiple distinct positions. At each position, the camera can either take a single image or dwell for a given period for acquiring a video.
Motif supports easy configuration and control of automated recording patterns with its built-in API and web based user interface. The scheduling feature can be used to automatically image the compartments without user intervention.
This XY gantry system can record from an area of 1330 x 900 mm and has a total height of ~450 mm. The camera can be moved to specific locations, or it can be controlled in a closed-loop fashion (e.g. for following a single subject). The light source, a thin LED panel, is fixed to the camera sled for achieving shadow-free illumination.
The area that can be covered with a gantry system reaches from a multi well-plate with super high resolution to a system that is up to 9sqm (3000 x 3000 mm) in size.
In both cases you might want to use a scripting language such as R or Python, to automatically retrieve
your video tracking results for further analysis.
In this short example we demonstrate how to use the API in Python to download and plot a
deep learning tracking result.
All Loopy documentation, including the API documentation, can be easily accessed by
clicking on 'Documentation' once logged in.
Interested in Loopy?
Loopy is software for 2D and 3D animal tracking, image processing, deep learning,
behavior coding, and analysis. Loopy is used through your web browser - there is
no software to install. New features are constantly added to Loopy and are immediately
available to all - without extra cost.
If you have a large research group Loopy on-site can be used by all members at once, with data
sharing and secure video storage. This keeps all you raw data and tracking results in one place
for security and organisation.
Throughout the year we continually worked on Loopy, adding new features and delivering them to customers. Loopy is a continually and freely
updated product, which means all new features we added were immediately available to the existing users.
We improved the behavioral coding / scoring features, and had a number of research groups and departments move over wholesale to using Loopy for their video coding, for example (case study here).
We added improved analysis and plotting (both 2D and 3D) of our pose tracking / keypoint tracking.
(left) Velocity timeseries of tracked object position. (right) X-Y-time plot of tracked object through the video. Correlated beak-tail motion is camera movement, otherwise the head is remarkably well stabilized. Made with #Loopy in 15 minutes (https://t.co/c2rYR068hM) pic.twitter.com/hIpb6BfH4k
We released Version 5 of Motif - our recording software which can be used standalone, or combined across multiple computers to build complex and automated
experimental assays. This was a significant release adding many new features, including the following highlights (more info).
I/O, DAQ, Sensor and Output Support
Motif can record data synchronized to the video, including reading from DAQ devices.
All data is stored in one file, making working with other data streams, such as EEG, audio, or optogenetic stimulation,
extremely easy. Motif can itself also control output to create complex experiments
Live Image Streaming / Real-time Closed-loop Image Processing Support
Motif can now stream or process video data in real-time. In combination with the above it makes the creation
of complicated experiments with stimuli very easy.
Windows and Increased Camera Support
Motif now runs on Windows, and supports even more types of cameras - more than 500.
Motif video recording software version 5 is released! 🍾🎉 New blog with details of the new features. #Motif is the solution for recording video and sensors for quantitative biology. One or many cameras, synchronized with neuro/eeg/ephys, it does it all. https://t.co/LYtphhDTVy
— loopbio quantitative biology (@loopbiogmbh) July 2, 2019
The new real-time features of this release allowed us to deliver real-time tracking and closed-loop assays to customers (and create this cool 70s demo).
— loopbio quantitative biology (@loopbiogmbh) August 27, 2019
We also exhibited for the very first time at our largest conference to-date, SFN - the society of neuroscience meeting in Chicago.
Great catching up with old friends at #SfN2019! @maxhofb and fellow pose tracking enthusiast (and expert 😜👨🏫) @talmop. Swing by booth 1854 to see how our video recording and variety of tracking solutions can support your science! #SfN19pic.twitter.com/YeMMkj9Bqw
To make room for the growth of loopbio, we moved from our previous office into a brand new premises in the center of Vienna, we can now be found at Lange Gasse 65/14 - 1080 Vienna!
New Office! 🍾🥳 We are super proud to be in our new premises at Lange Gasse 65/14 Vienna (stop by if in town). From humble beginnings in Kritzendorf we've had 4 years of fun helping scientists around the world, and look forward to many more years of success! pic.twitter.com/slLKazgHRp
We partnered with Traverse Science to bring the power of Loopy tracking, analysis and behavior recognition to the large-animal and pre-clinical North American market.
We are super excited to work with @TraverseScience, supporting preclinical, neuroscience and nutrition research, and quantitative analysis of large animal 🐖 behavior! https://t.co/PYjYI2l4eK
 Loopy’s Behavioral Coding tool.
Loopy’s Behavioral Coding tool.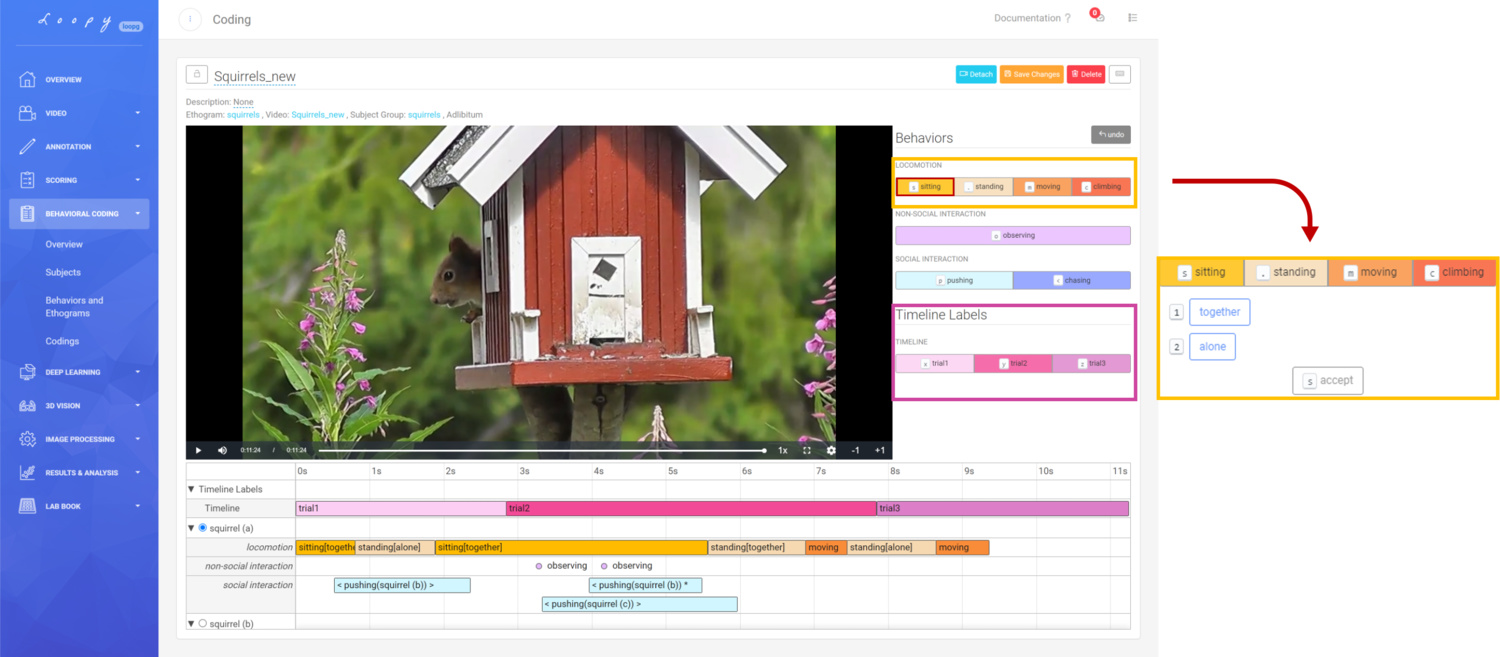 A video coded with Loopy showcasing our newest features (Modifiers and Timeline Labels).
A video coded with Loopy showcasing our newest features (Modifiers and Timeline Labels).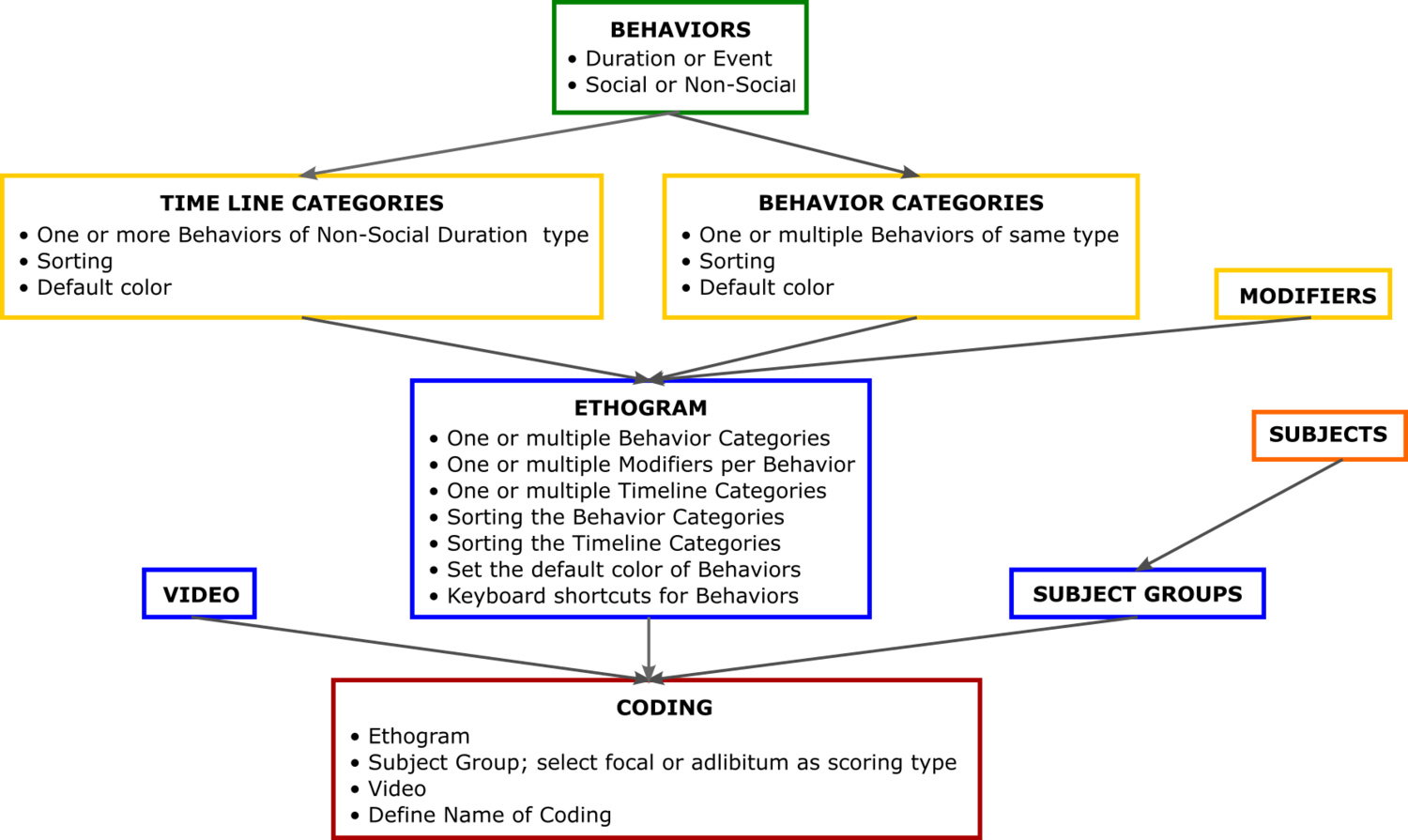 A schematic of the different elements included in Loopy’s Behavioral Coding tool.
A schematic of the different elements included in Loopy’s Behavioral Coding tool.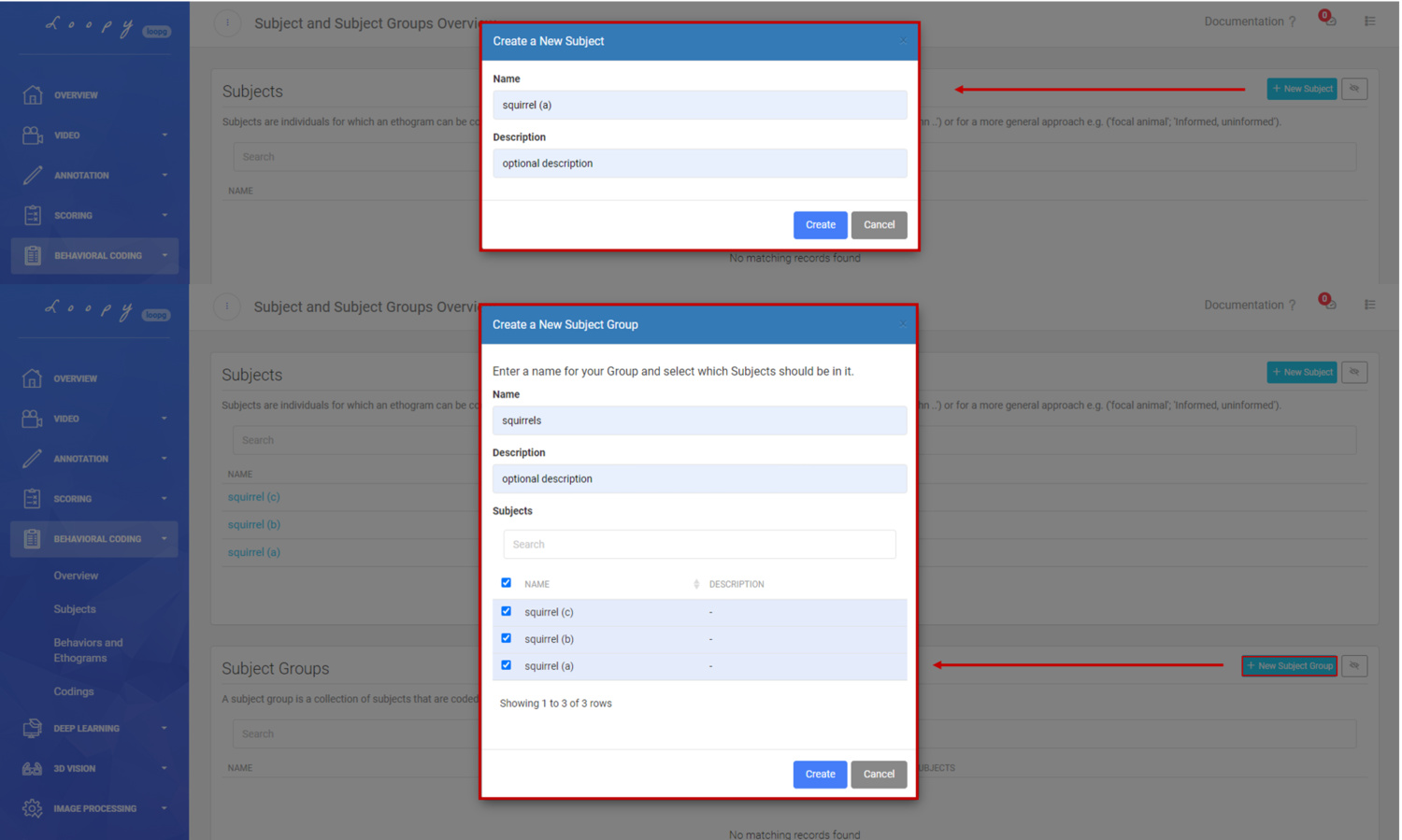 How to create a Subject and a Subject Group.
How to create a Subject and a Subject Group.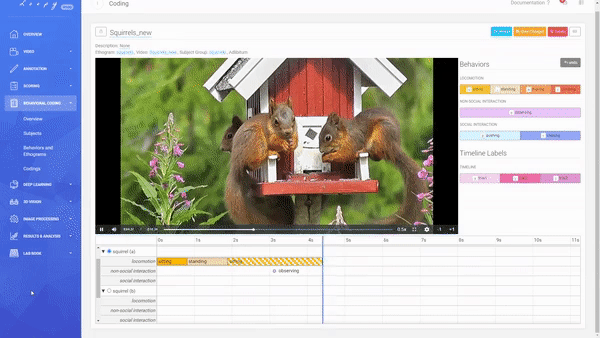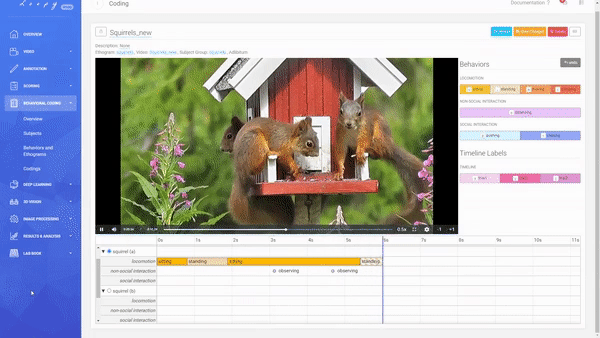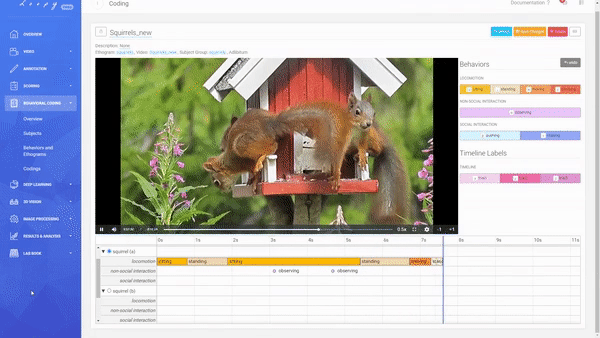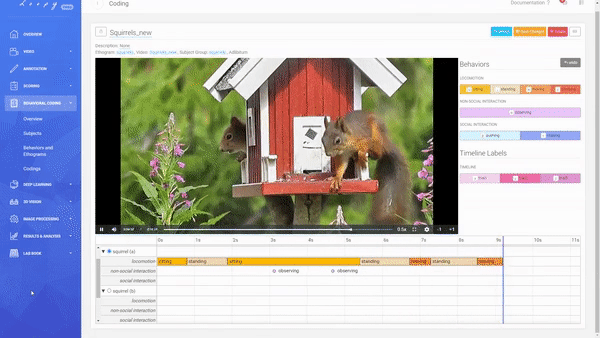 Examples of Durations and Events.
Examples of Durations and Events.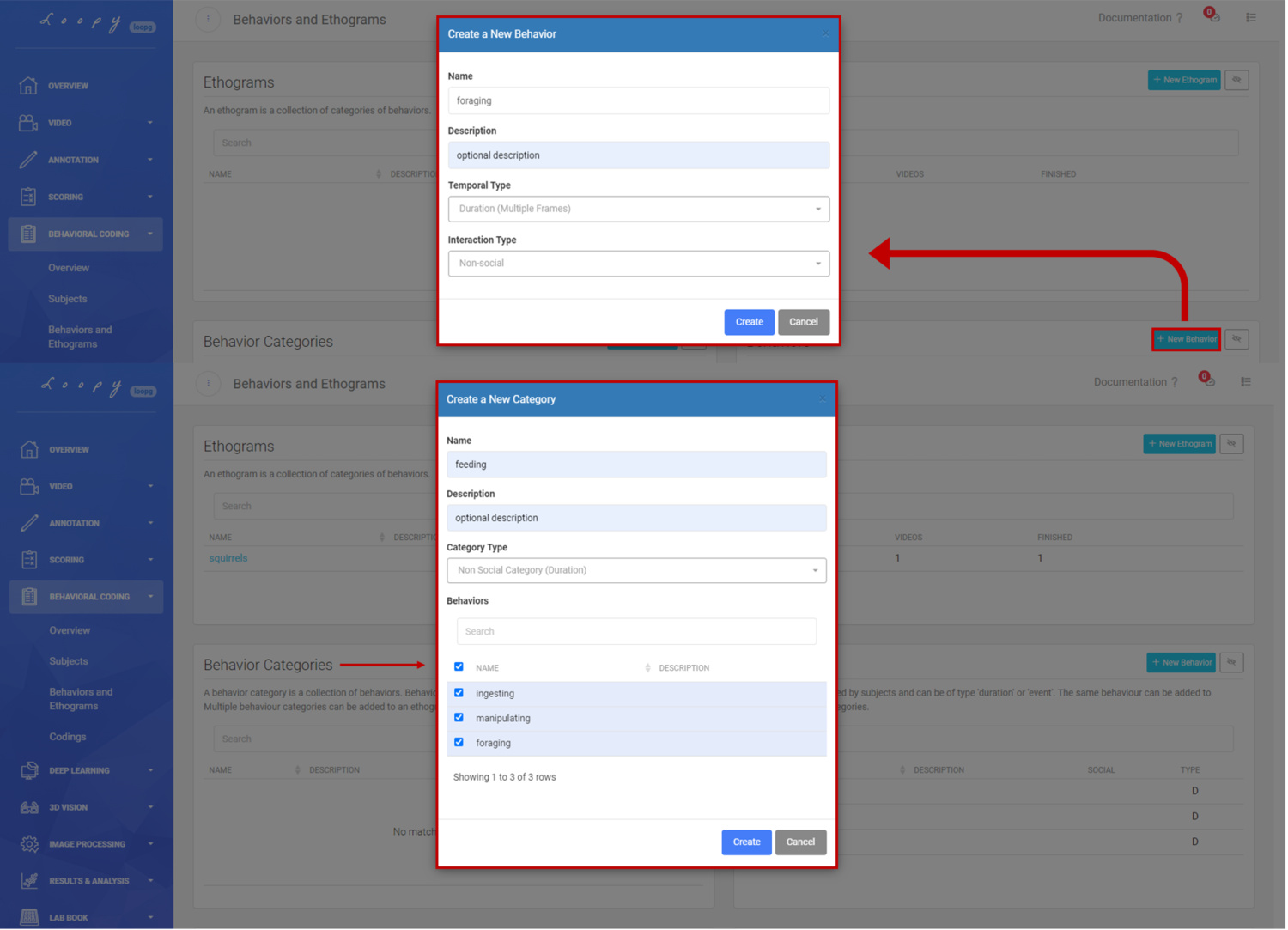 Creating a new Behavior and Behavior Category.
Creating a new Behavior and Behavior Category.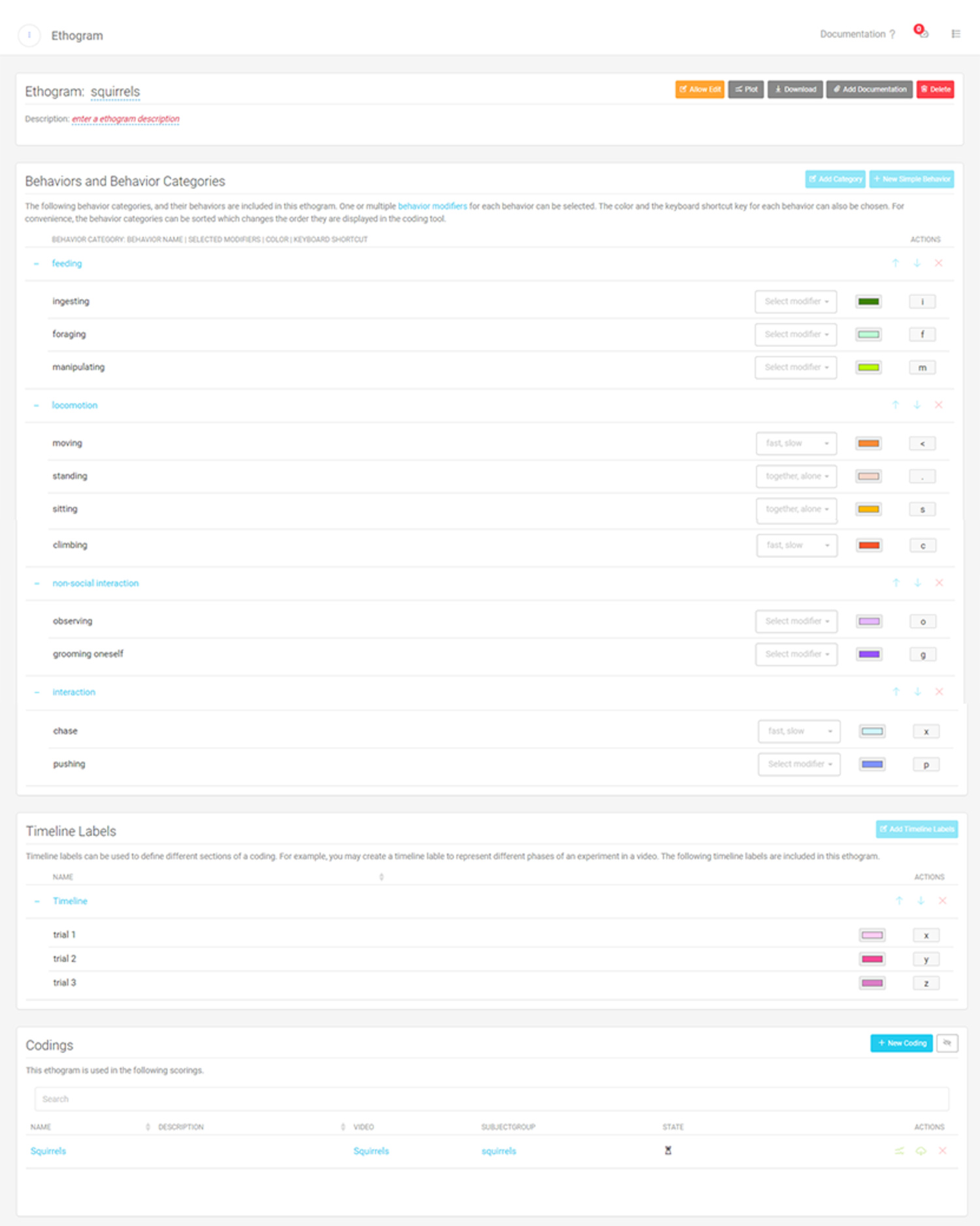 An Ethogram with multiple Behaviours in multiple Behaviour Categories, Timeline Labels, Modifiers and keyboard shortcuts.
An Ethogram with multiple Behaviours in multiple Behaviour Categories, Timeline Labels, Modifiers and keyboard shortcuts.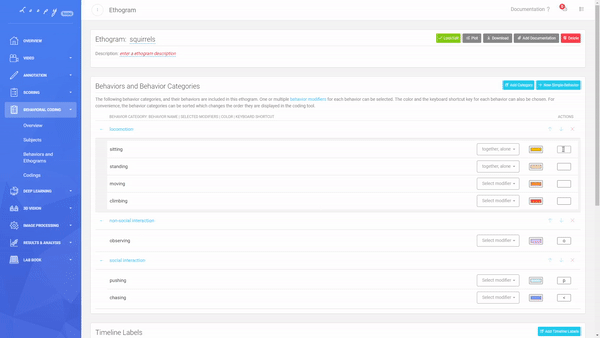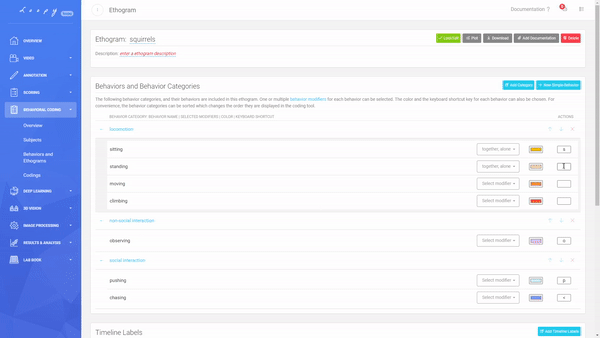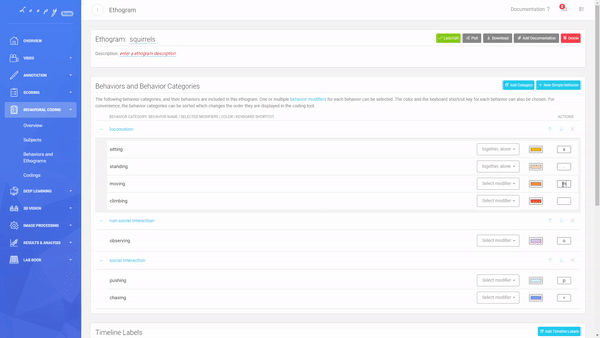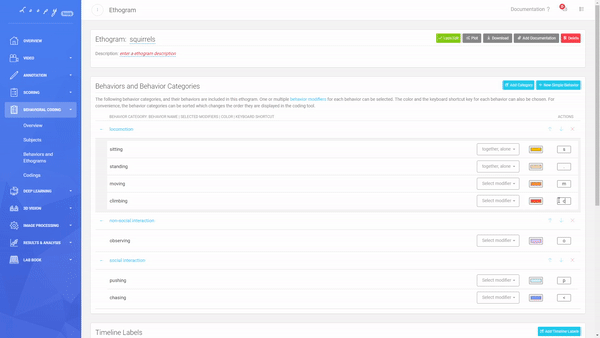 Create your own Keyboard Shortcuts.
Create your own Keyboard Shortcuts.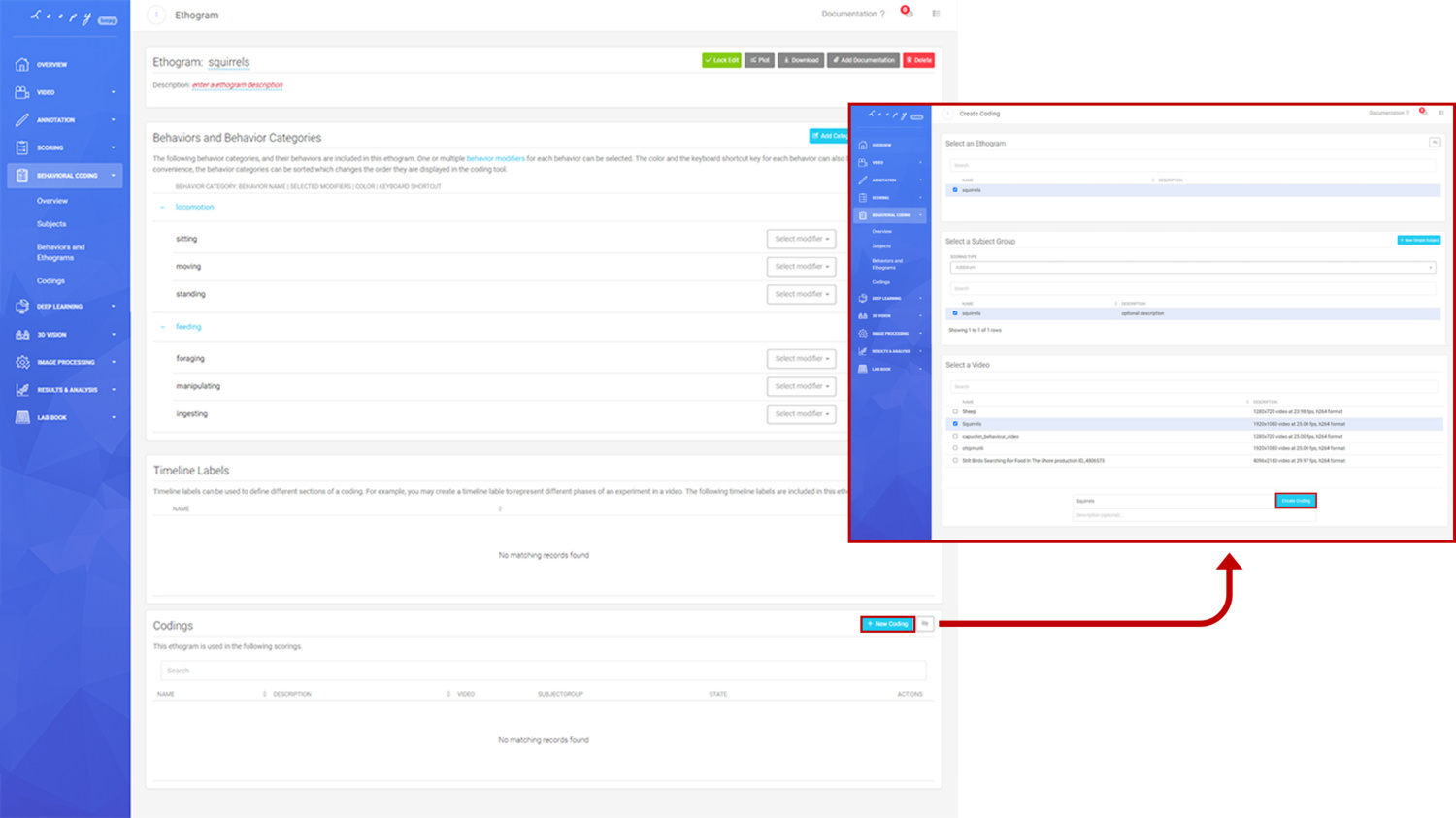 Creating a new Coding.
Creating a new Coding.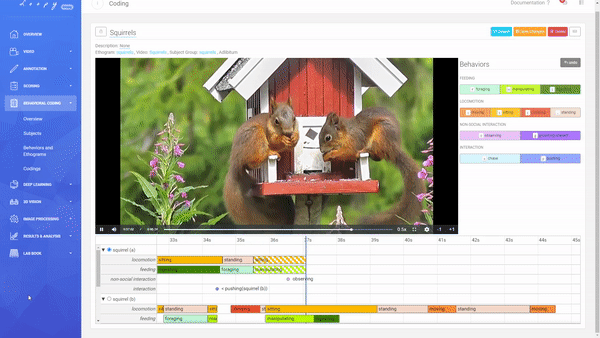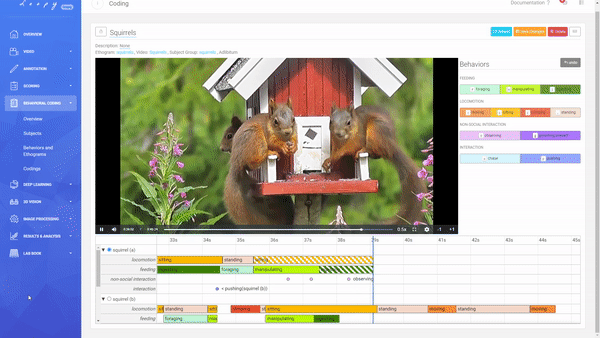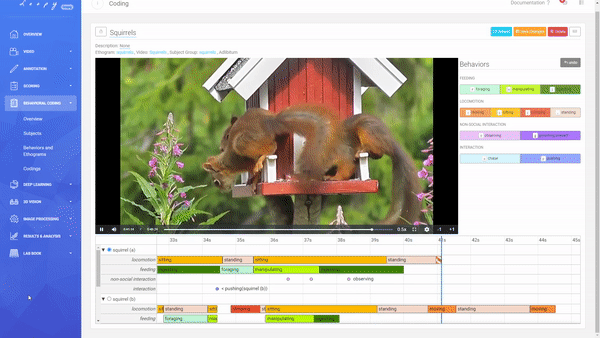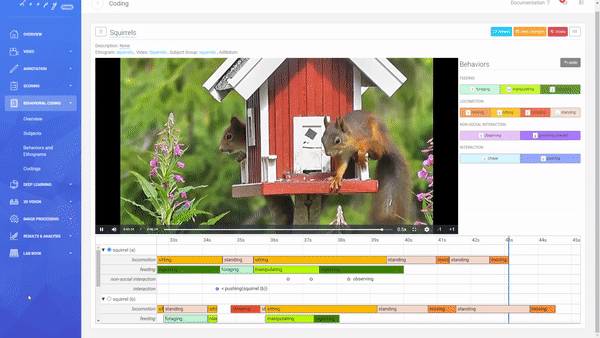 Code Durations and Events.
Code Durations and Events.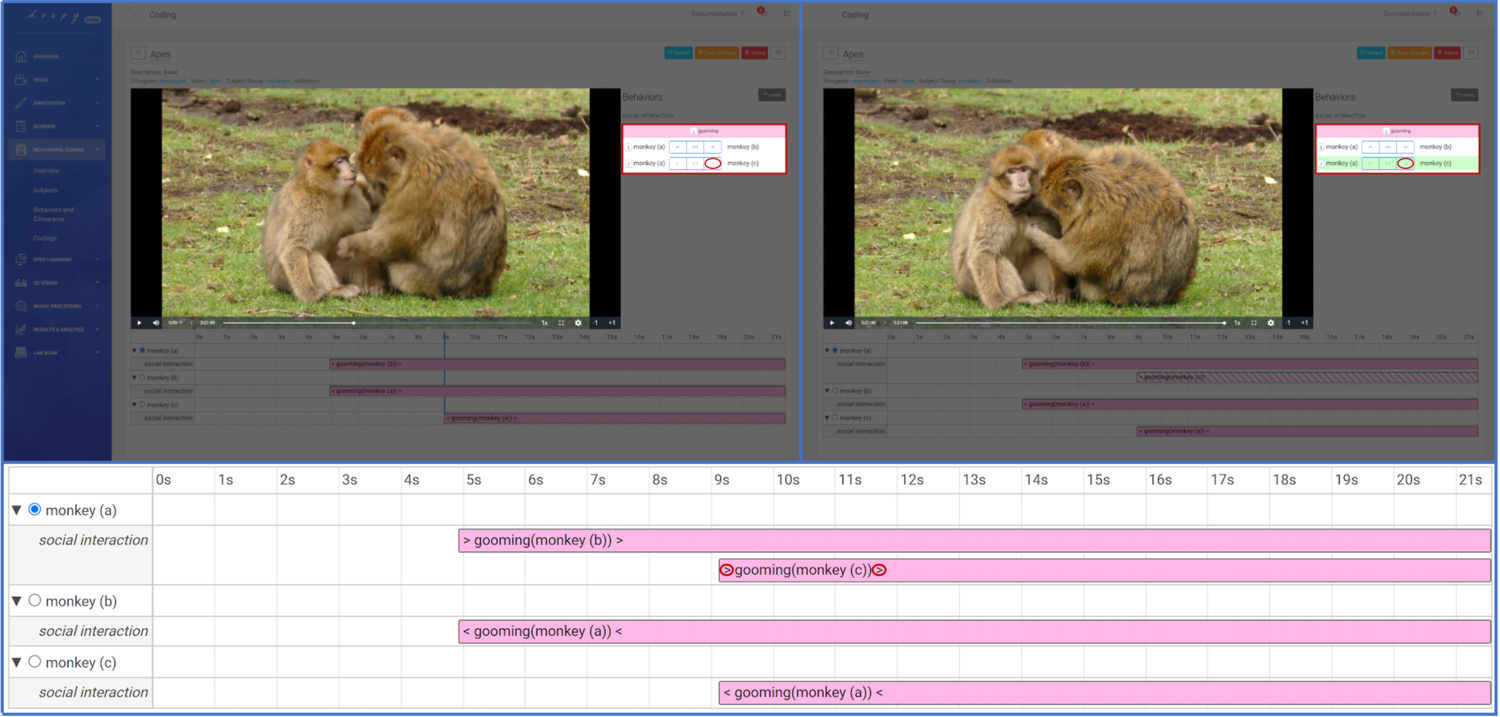 Coding social interactions.
Coding social interactions. Coding a Social Duration Behavior Category with two Behaviors (laying together, sitting together) for the Focal Subject "squirrel (a)" with its two partners "squirrel (b)" and "squirrel (c)".
Coding a Social Duration Behavior Category with two Behaviors (laying together, sitting together) for the Focal Subject "squirrel (a)" with its two partners "squirrel (b)" and "squirrel (c)".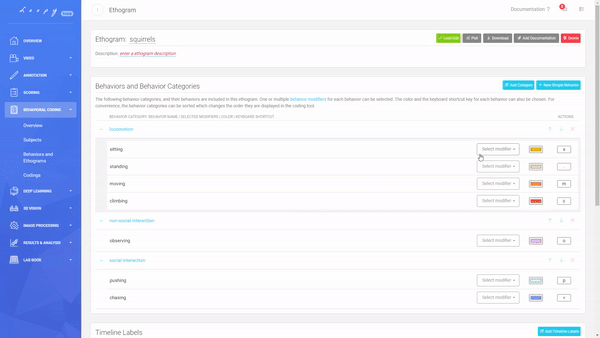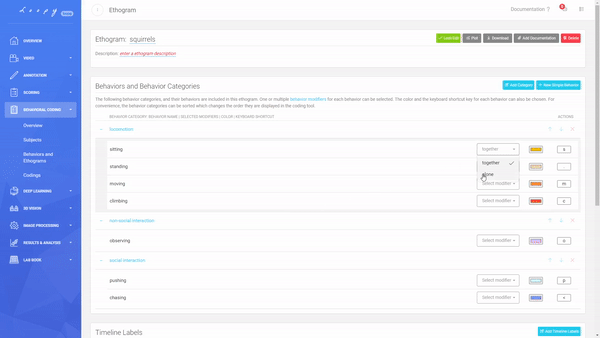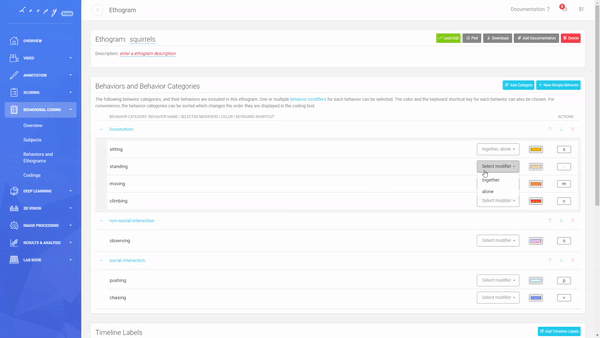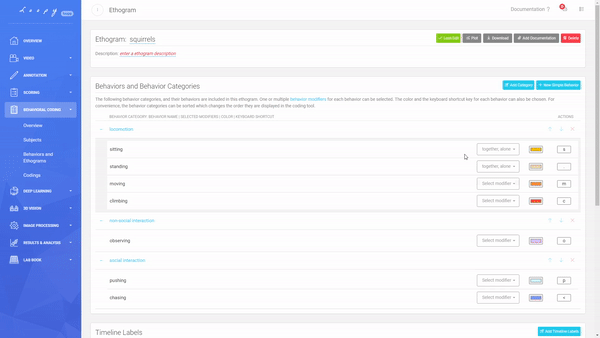 Define the Modifiers you want to use in your coding.
Define the Modifiers you want to use in your coding.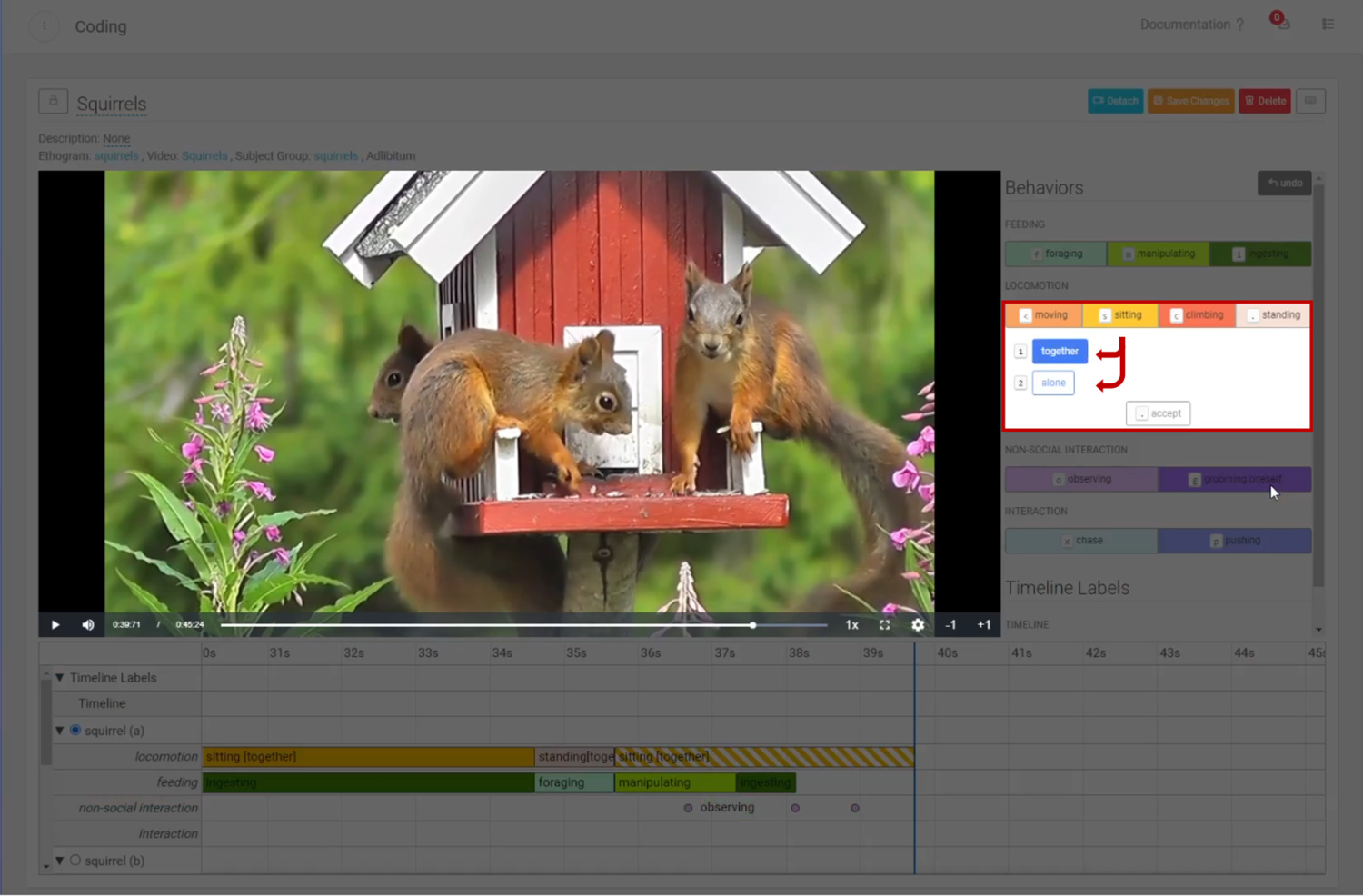 Coding a Duration Behavior with Modifiers.
Coding a Duration Behavior with Modifiers.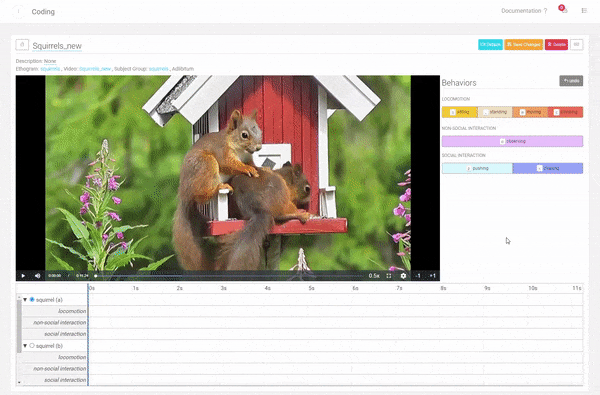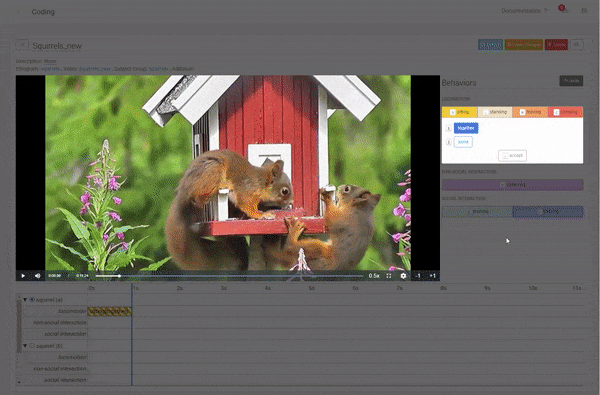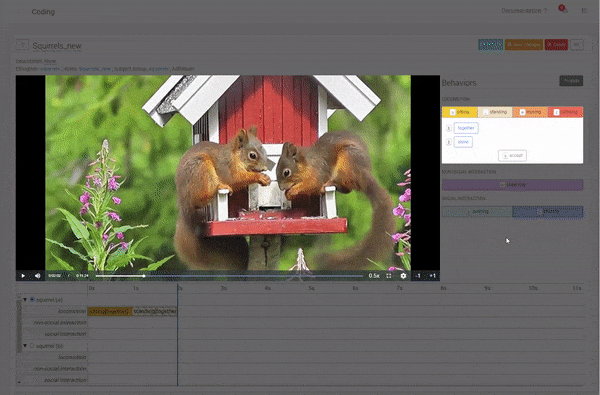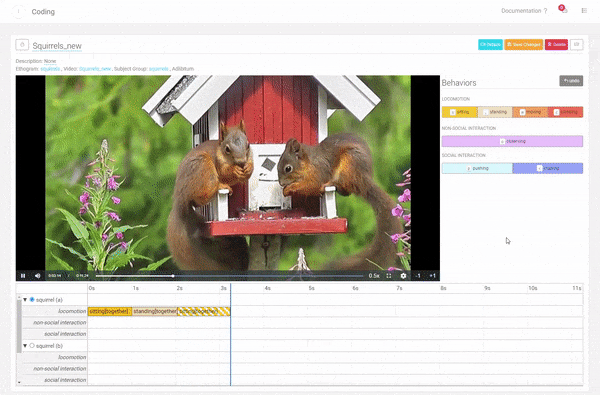 Code including your Modifiers.
Code including your Modifiers.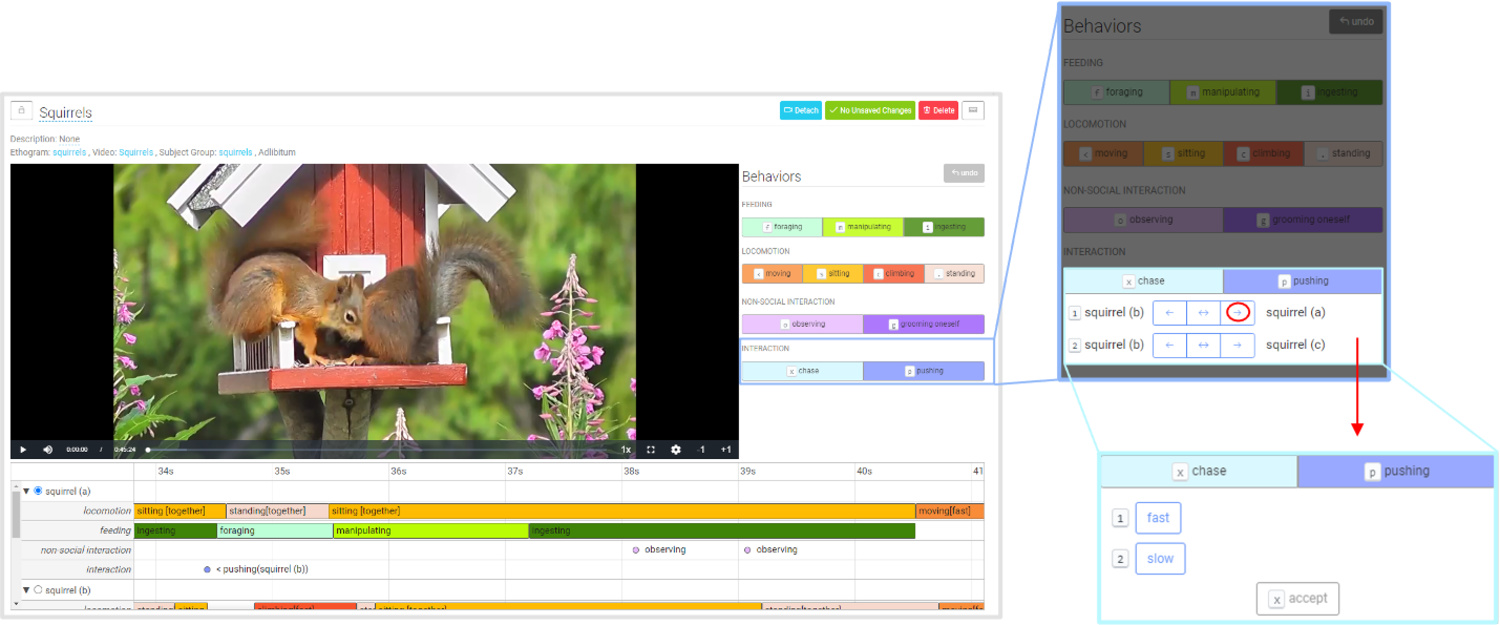 Coding a social interaction with Modifiers.
Coding a social interaction with Modifiers.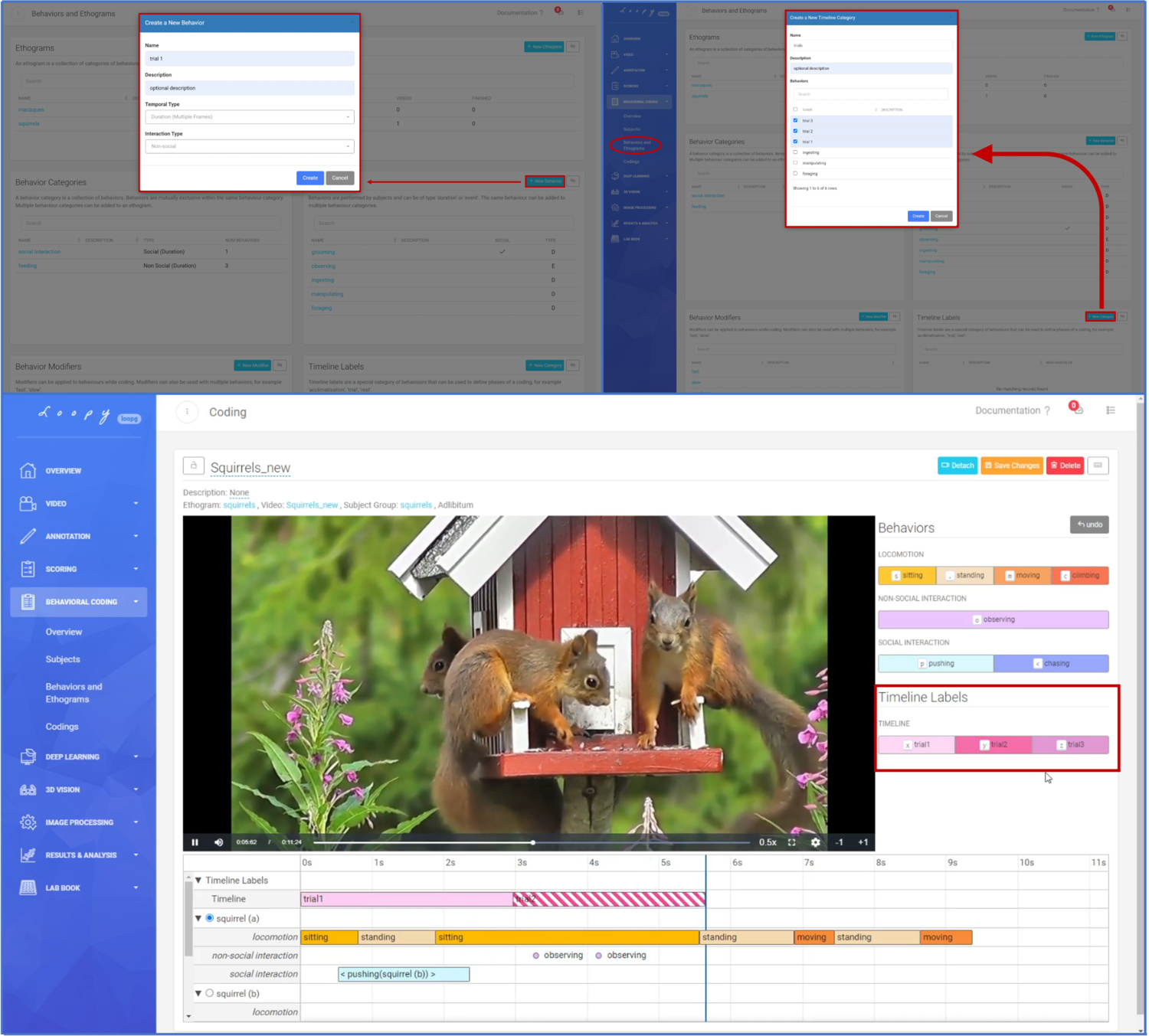 Using Timeline Labels for organizing video segments.
Using Timeline Labels for organizing video segments.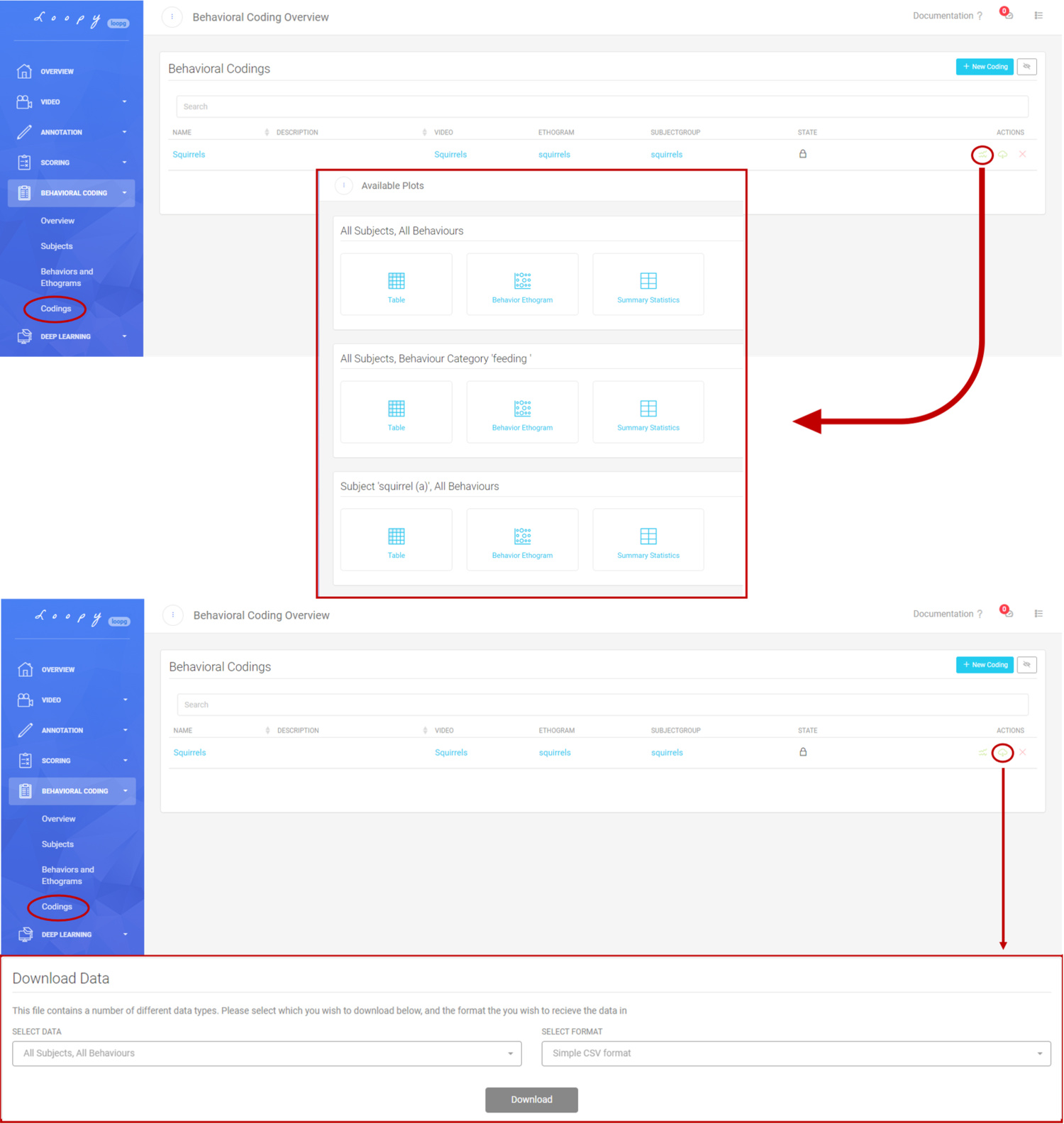 Plots and Downloading data.
Plots and Downloading data.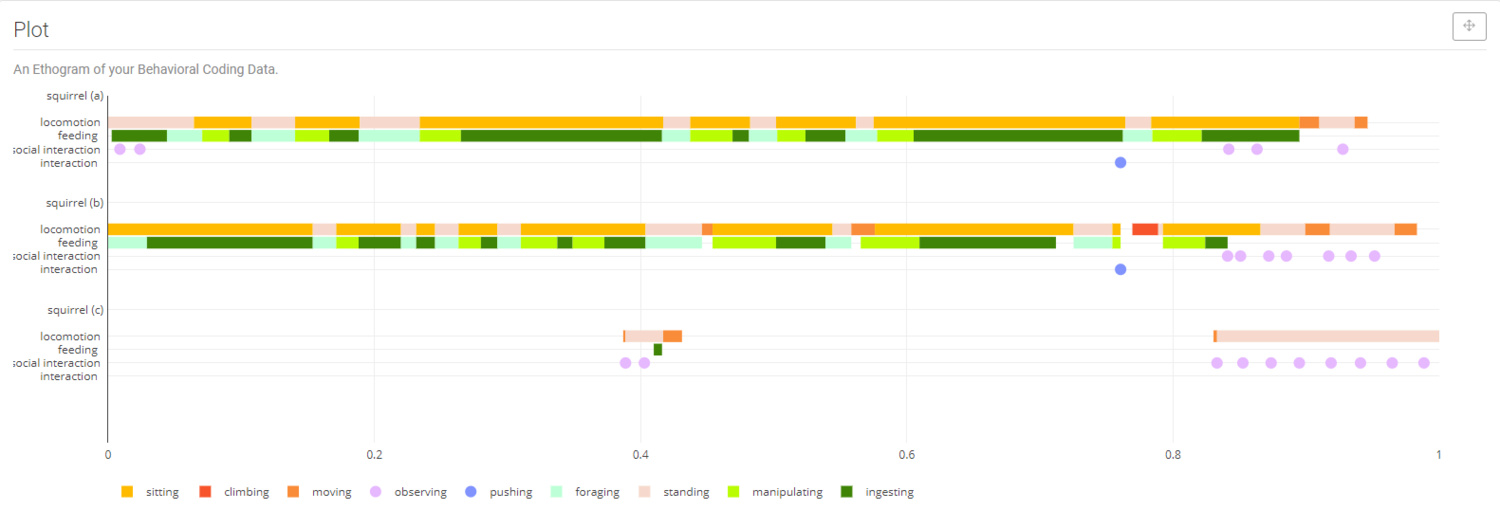 Plot your data as a Behavior Ethogram.
Plot your data as a Behavior Ethogram.
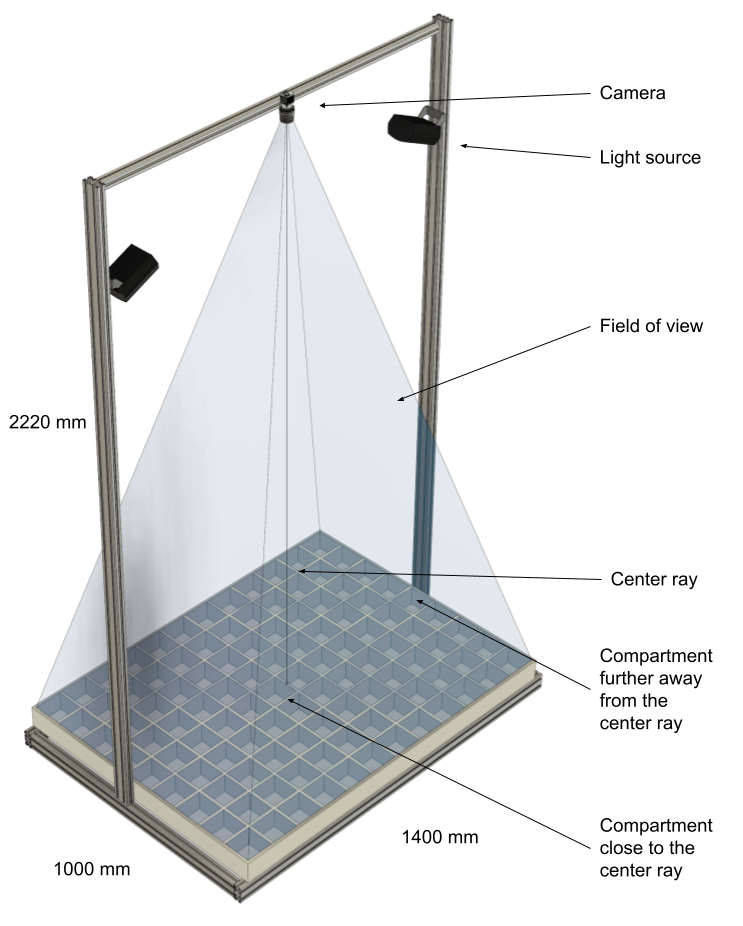 An example system with lighting (visual and/or near infrared) for recording 108 compartments.
An example system with lighting (visual and/or near infrared) for recording 108 compartments.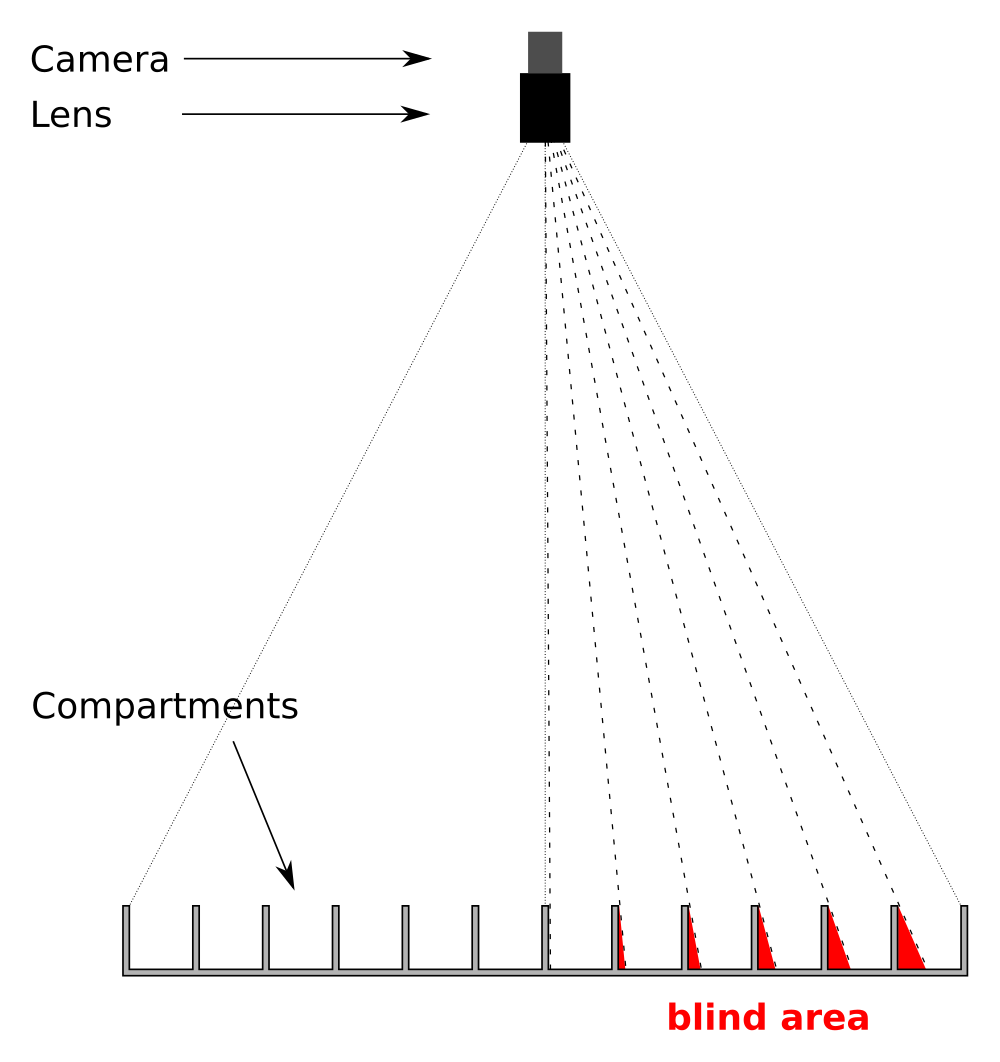 Blind spots will be present in all configurations where a single camera records many compartments
Blind spots will be present in all configurations where a single camera records many compartments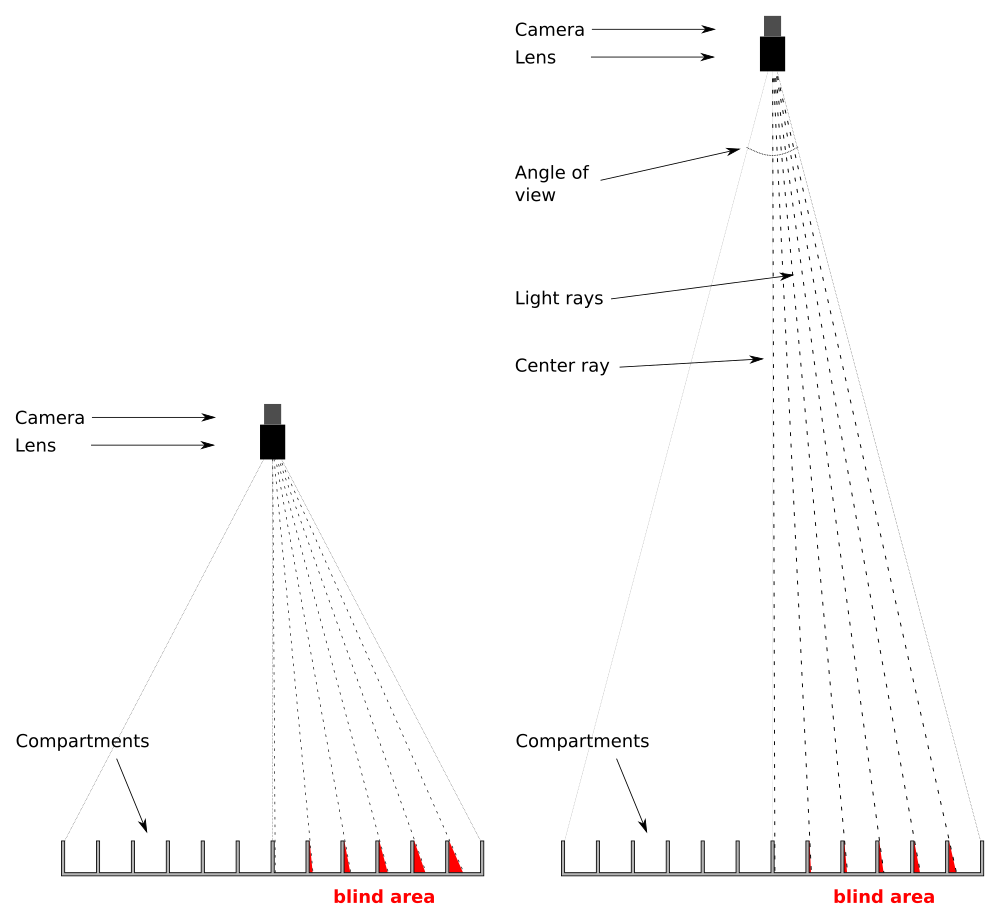 A comparison of camera-rays when mounted close to or far from the compartments. Cameras mounted close to compartments cast larger blind areas whereas cameras mounted further away from compartments reduces blind areas
A comparison of camera-rays when mounted close to or far from the compartments. Cameras mounted close to compartments cast larger blind areas whereas cameras mounted further away from compartments reduces blind areas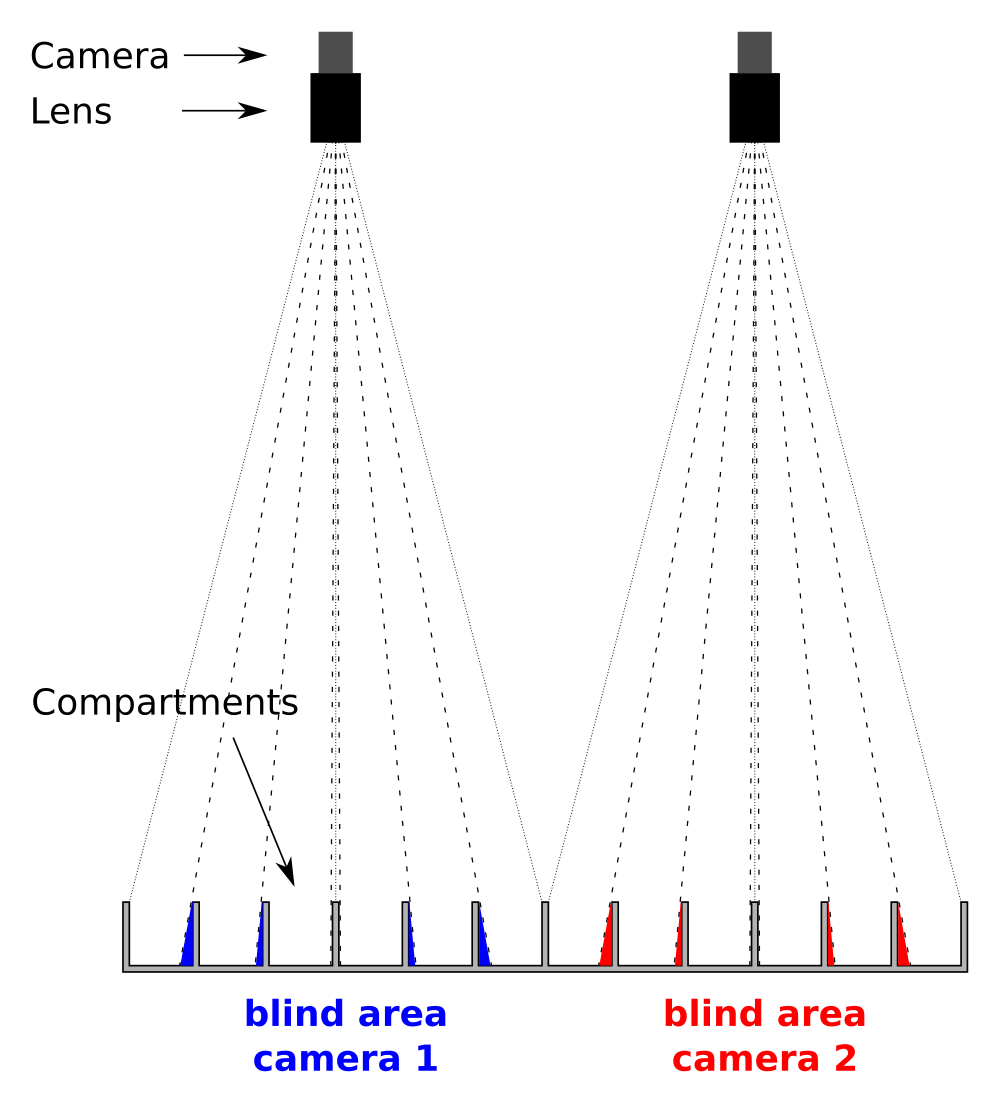 Multiple cameras viewing subsections of an arena reduces the size of the blind area and can be used for increasing spatial resolution and frame rate
Multiple cameras viewing subsections of an arena reduces the size of the blind area and can be used for increasing spatial resolution and frame rate Increasing the distance between the compartments and the camera can be achieved with mirror arrangements
Increasing the distance between the compartments and the camera can be achieved with mirror arrangements
 A representative telecentric lens attached to a camera captures an orthographic view of the arena.
A representative telecentric lens attached to a camera captures an orthographic view of the arena.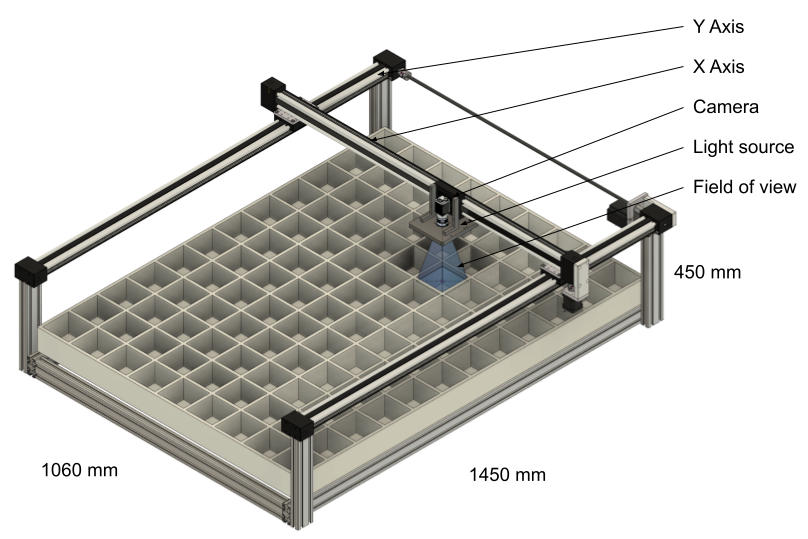 This XY gantry system can record from an area of 1330 x 900 mm and has a total height of ~450 mm. The camera can be moved to specific locations, or it can be controlled in a closed-loop fashion (e.g. for following a single subject). The light source, a thin LED panel, is fixed to the camera sled for achieving shadow-free illumination.
This XY gantry system can record from an area of 1330 x 900 mm and has a total height of ~450 mm. The camera can be moved to specific locations, or it can be controlled in a closed-loop fashion (e.g. for following a single subject). The light source, a thin LED panel, is fixed to the camera sled for achieving shadow-free illumination.